
Chapter: Transcription, RNA Processing, and Translation
Introduction to Gene Expression
DNA stores the hereditary information of life, but DNA itself does not directly perform most cellular functions. Instead, the information encoded within DNA must first be copied into RNA and then translated into proteins. Proteins carry out most of the structural, enzymatic, and regulatory functions within a cell. The overall process by which information stored in DNA becomes a functional protein is known as gene expression. Gene expression occurs in two major stages: transcription and translation. Transcription is the process by which the information stored in DNA is copied into RNA. Translation is the process by which the nucleotide sequence of RNA is converted into the amino acid sequence of a protein. The relationship between DNA, RNA, and proteins is often referred to as the central dogma of molecular biology: DNA → RNA → Protein. This flow of information forms the basis for nearly all cellular activities.
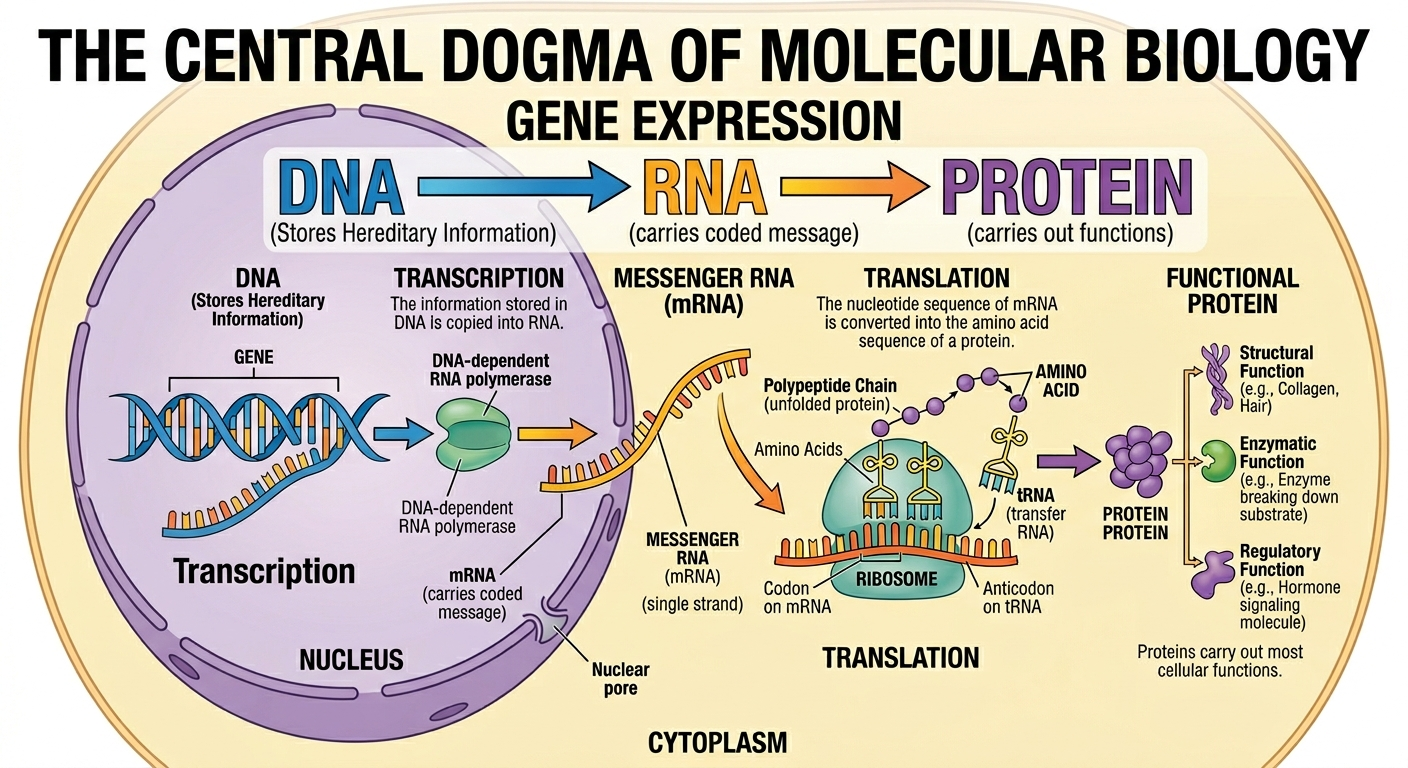
Figure 1. The central dogma of molecular biology describes the flow of genetic information from DNA to RNA to protein.
Structure of DNA and RNA
RNA, or ribonucleic acid, is chemically similar to DNA but differs in several important ways. RNA contains the sugar ribose rather than DNA’s deoxyribose, and ribose possesses an additional oxygen atom on the 2’ carbon of the sugar molecule. RNA also uses the nitrogenous base uracil where as DNA utilizes thymine. RNA is usually single-stranded, while DNA is double-stranded. The monomers of RNA are known as ribonucleotides, and like DNA’s deoxribonucleotides, they are connected by phosphodiester bonds producing an RNA strand with 5’ to 3’ directionality.
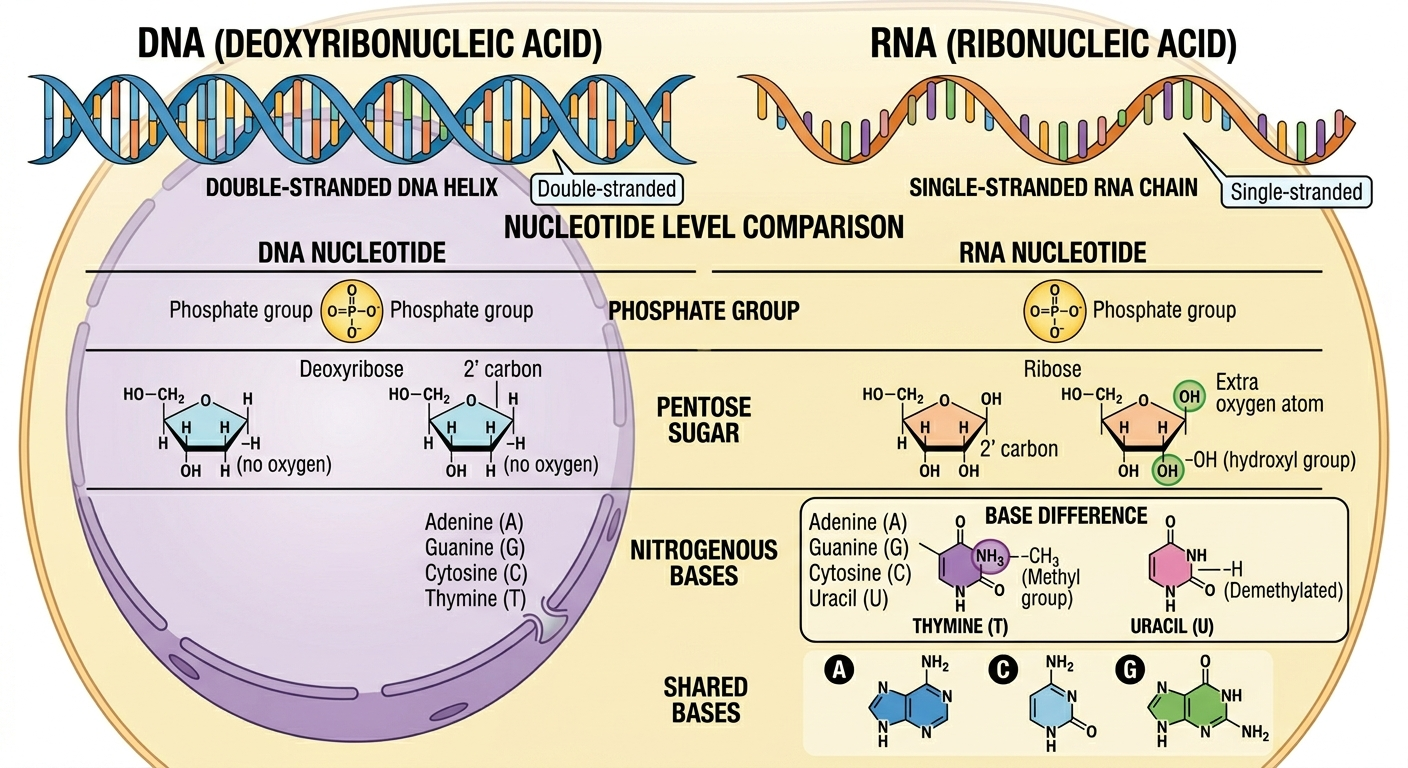
Figure 2. RNA differs from DNA in sugar composition, nitrogenous bases, and strand structure.
Types of RNA
Cells contain several major forms of RNA, each with a specialized role in gene expression and cellular function. Although RNA is generally single stranded, different RNA molecules vary greatly in structure and function. Messenger RNA (mRNA) carries genetic instructions copied from DNA to ribosomes, where proteins are synthesized. In eukaryotes, newly transcribed RNA is processed by adding a 5′ cap, a poly-A tail, and removing introns through RNA splicing. The mature mRNA contains codons that specify the amino acid sequence of a protein. Transfer RNA (tRNA) delivers amino acids to the ribosome during translation. Each tRNA carries a specific amino acid and contains an anticodon that pairs with a complementary codon on the mRNA. This ensures that amino acids are added in the correct order during protein synthesis. Ribosomal RNA (rRNA) combines with proteins to form ribosomes, the structures responsible for translation. In addition to providing structural support, rRNA also catalyzes peptide bond formation between amino acids, making it a ribozyme.
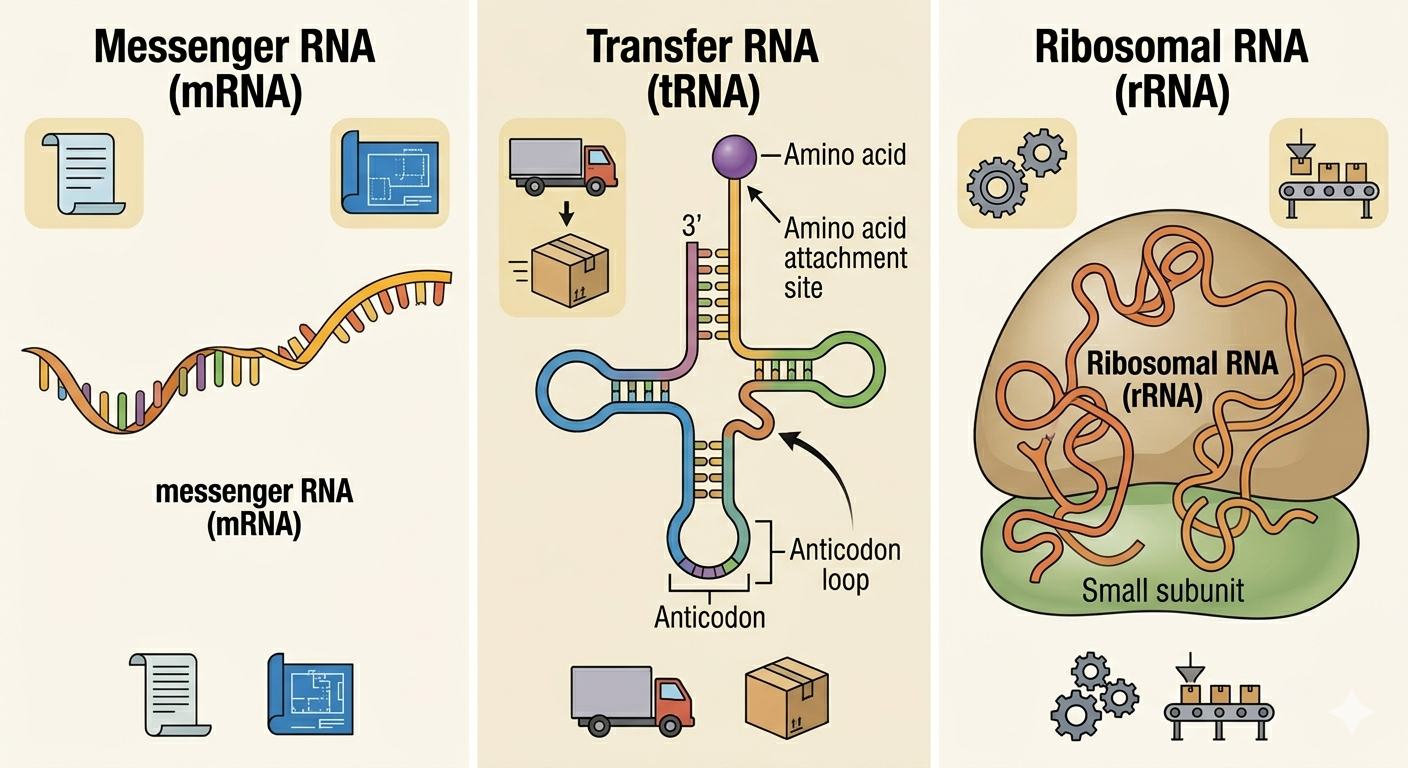
Figure 3. Different forms of RNA perform specialized roles in gene expression.
Transcription
Transcription is the process by which RNA is synthesized using DNA as a template. During transcription, one strand of DNA serves as the template strand, and RNA nucleotides pair with exposed DNA nucleotides according to complementary base pairing rules. The opposite DNA strand is known as the coding strand and it possesses nearly the same sequence as the RNA transcript except that RNA contains uracil in place of thymine. RNA synthesis occurs in the 5’ to 3’ direction, meaning ribonucleotides are added only to the 3’ end of the growing RNA strand. Unlike DNA replication, transcription usually copies only a specific section of DNA corresponding to a single segment of RNA, known as a gene.
Figure 4. During transcription, RNA polymerase synthesizes RNA using one DNA strand as a template.
RNA Polymerase
The enzyme responsible for RNA synthesis is RNA polymerase. RNA polymerase synthesizes RNA by joining ribonucleotides together using phosphodiester bonds while reading the DNA template strand. RNA polymerase functions similarly to DNA polymerase in several respects, but unlike DNA polymerase, RNA polymerase does not require a primer to begin synthesis. RNA polymerase can initiate RNA synthesis directly and temporarily opens the DNA double helix itself during transcription. Bacteria possess a single type of RNA polymerase capable of synthesizing all forms of RNA, whereas eukaryotic cells possess three primary RNA polymerases. RNA polymerase I synthesizes most ribosomal RNA, RNA polymerase II synthesizes messenger RNA and several regulatory RNAs, and RNA polymerase III synthesizes transfer RNA and some additional small RNAs.
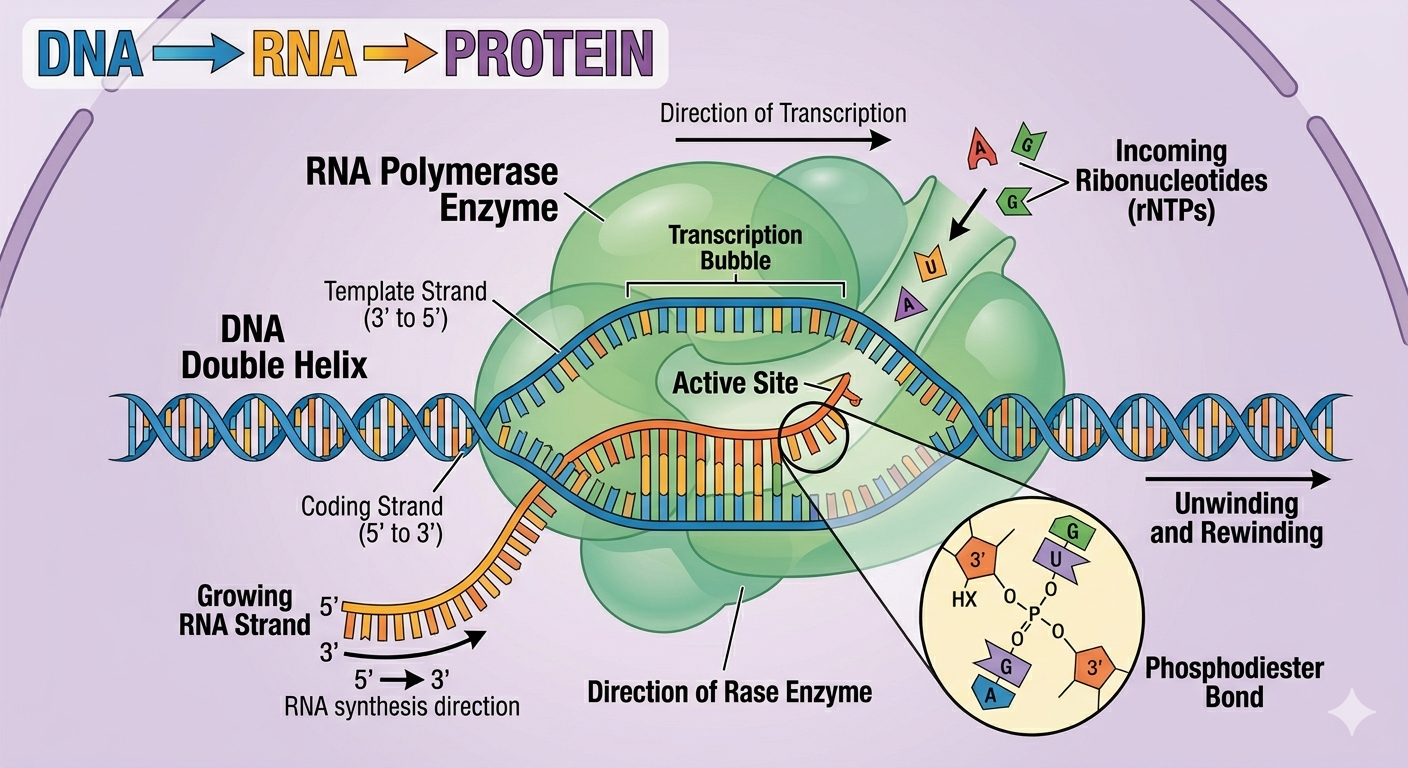
Figure 5. RNA polymerase synthesizes RNA in the 5’ to 3’ direction without requiring a primer.
Initiation of Transcription in Prokaryotes
Transcription begins at specific DNA sequences known as promoters. Cells contain many different genes, and each gene typically contains the instructions for producing a particular protein or functional RNA molecule (which codes for a specific protein). Genes are not always active; instead, they are turned on or off depending on the needs of the cell and environmental conditions. When a gene is activated, RNA polymerase binds to the promoter region and begins transcribing the DNA sequence into RNA.
In bacteria, transcription is initiated by a protein known as sigma factor, which binds to promoter sequences and guides RNA polymerase to the correct starting point on the DNA. Different sigma factors recognize different promoter sequences, allowing bacterial cells to selectively activate different groups of genes in response to environmental conditions. Once the sigma factor binds to the promoter, RNA polymerase attaches to the sigma factor-DNA complex and locally unwinds the DNA double helix, exposing the template strand. Ribonucleotides enter the active site of RNA polymerase and pair with complementary DNA bases according to base pairing rules. Once several ribonucleotides have been joined together, the sigma factor detaches from the complex and can be reused elsewhere, and transcription enters the elongation phase.

Figure 6. In bacteria, sigma factors guide RNA polymerase to promoter sequences initiating transcription.
Elongation of Transcription
During elongation, RNA polymerase moves along the DNA template strand synthesizing RNA. As RNA polymerase travels down the DNA molecule, it continuously unwinds a short section of DNA ahead of itself while incoming ribonucleotides pair with exposed DNA bases according to complementary base pairing rules. RNA polymerase catalyzes the formation of phosphodiester bonds between adjacent ribonucleotides, causing the RNA transcript to elongate continuously at its 3’ end. Behind the RNA polymerase, the DNA strands reassociate and reform the double helix while the growing RNA strand exits the RNA polymerase as synthesis continues. Unlike DNA replication, transcription copies only one DNA strand and does not permanently alter the DNA molecule.
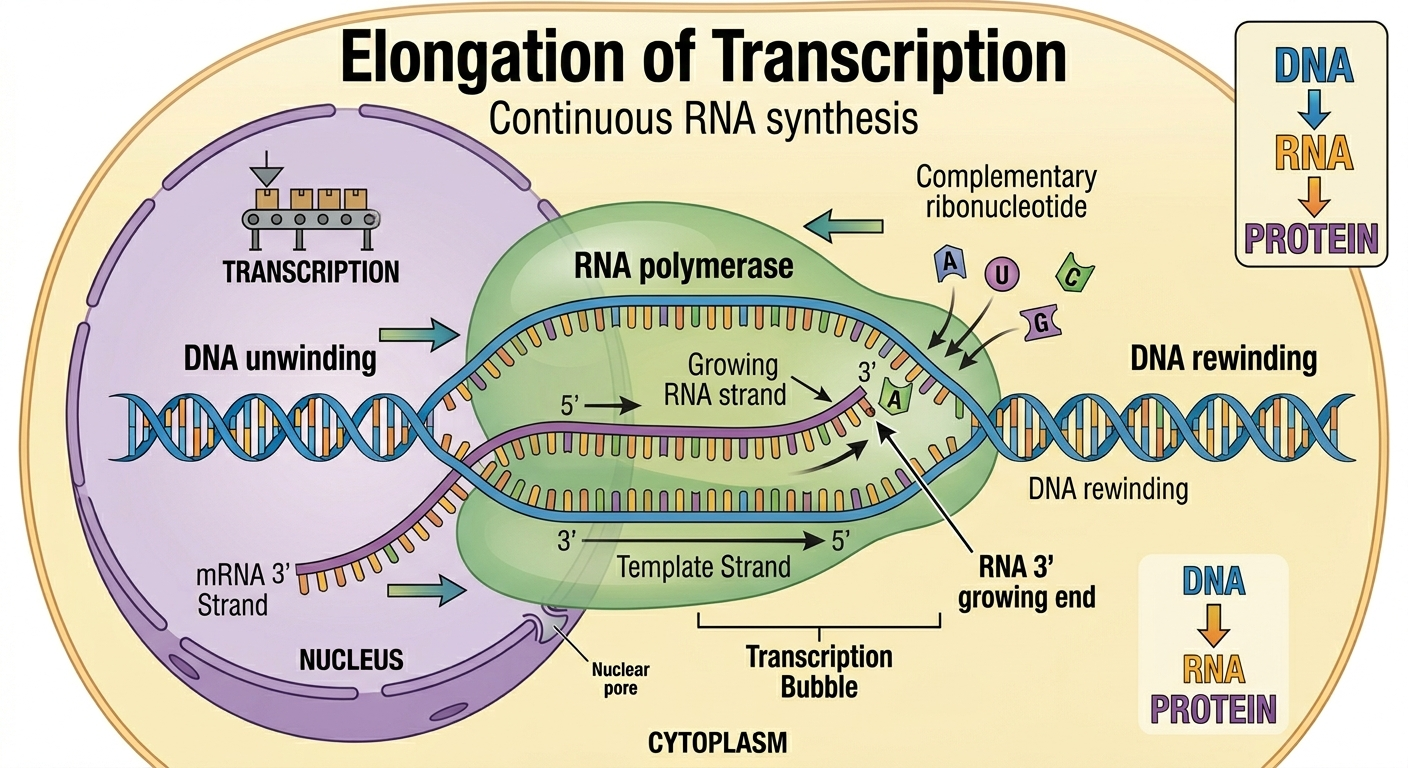
Figure 7. During elongation, RNA polymerase continuously synthesizes a growing RNA strand while steadily translocating along the DNA template.
Termination of Transcription in Prokaryotes
Transcription ends when RNA polymerase encounters a termination signal. In bacteria, one common termination mechanism involves the formation of an RNA hairpin. As a specific sequence of RNA is synthesized, complementary bases within the RNA molecule pair with each other, causing the RNA to fold back upon itself into a double-stranded stem-loop structure called a hairpin. The hairpin destabilizes the interaction between the RNA transcript and the DNA template, resulting in the release of the RNA transcript, detachment of RNA polymerase from the DNA, and complete reformation of the DNA double helix.
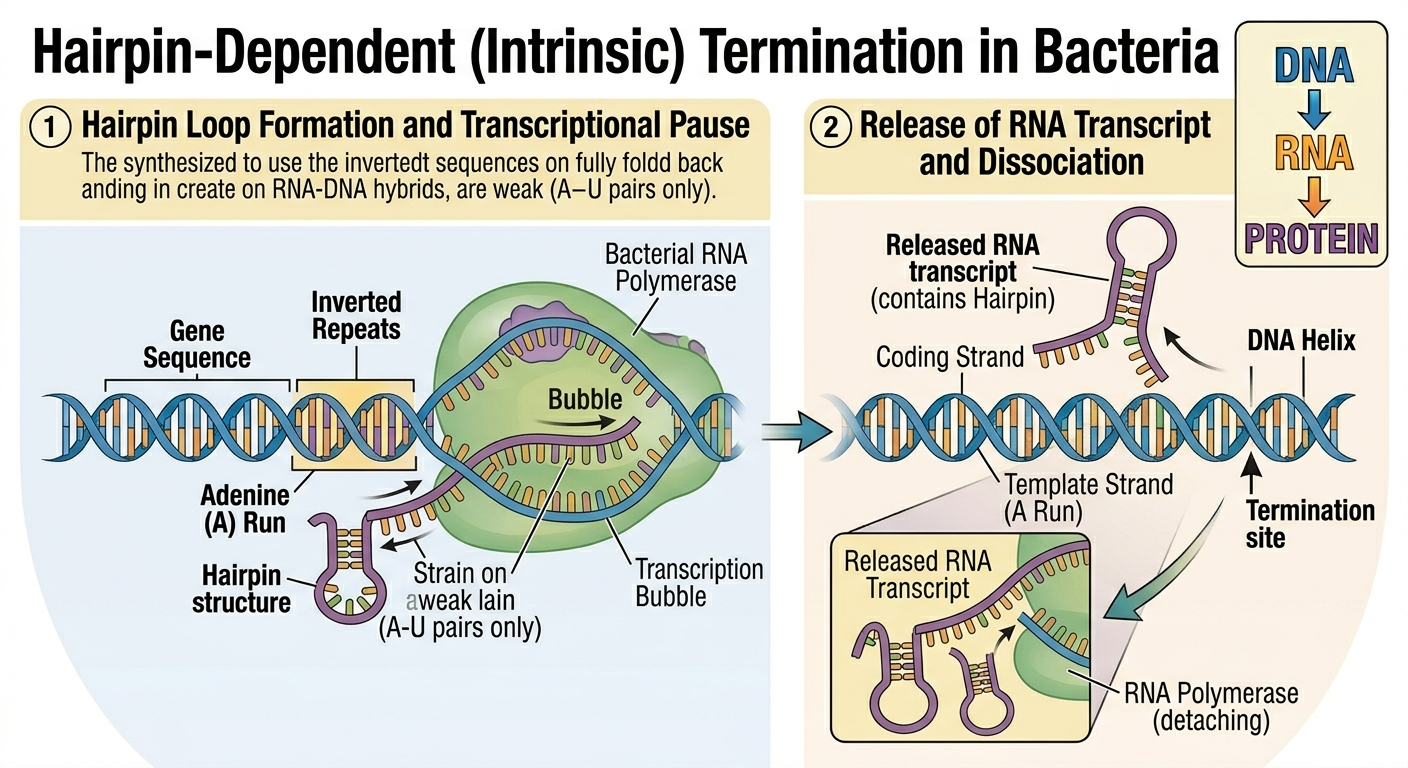
Figure 8. Formation of an RNA hairpin structure destabilizes the transcription complex and frequently leads to premature termination in many bacterial genes.
Transcription in Eukaryotes
The overall mechanism of transcription in eukaryotes is fundamentally similar to that of prokaryotes, but several important differences exist. Eukaryotic DNA is enclosed within a nucleus. Rather than relying on sigma factors, eukaryotic transcription requires numerous proteins known as transcription factors that assemble at the promoter region along with RNA polymerase II to form a transcription initiation complex. One important promoter sequence in many eukaryotic genes is the TATA box. Once the transcription complex assembles, RNA polymerase II unwinds the DNA and begins RNA synthesis. Elongation proceeds similarly to bacterial transcription, but termination differs because proteins cleave the newly synthesized RNA transcript before RNA polymerase eventually detaches from the DNA template. Unlike bacterial mRNA, eukaryotic RNA transcripts usually require extensive processing before they become functional.
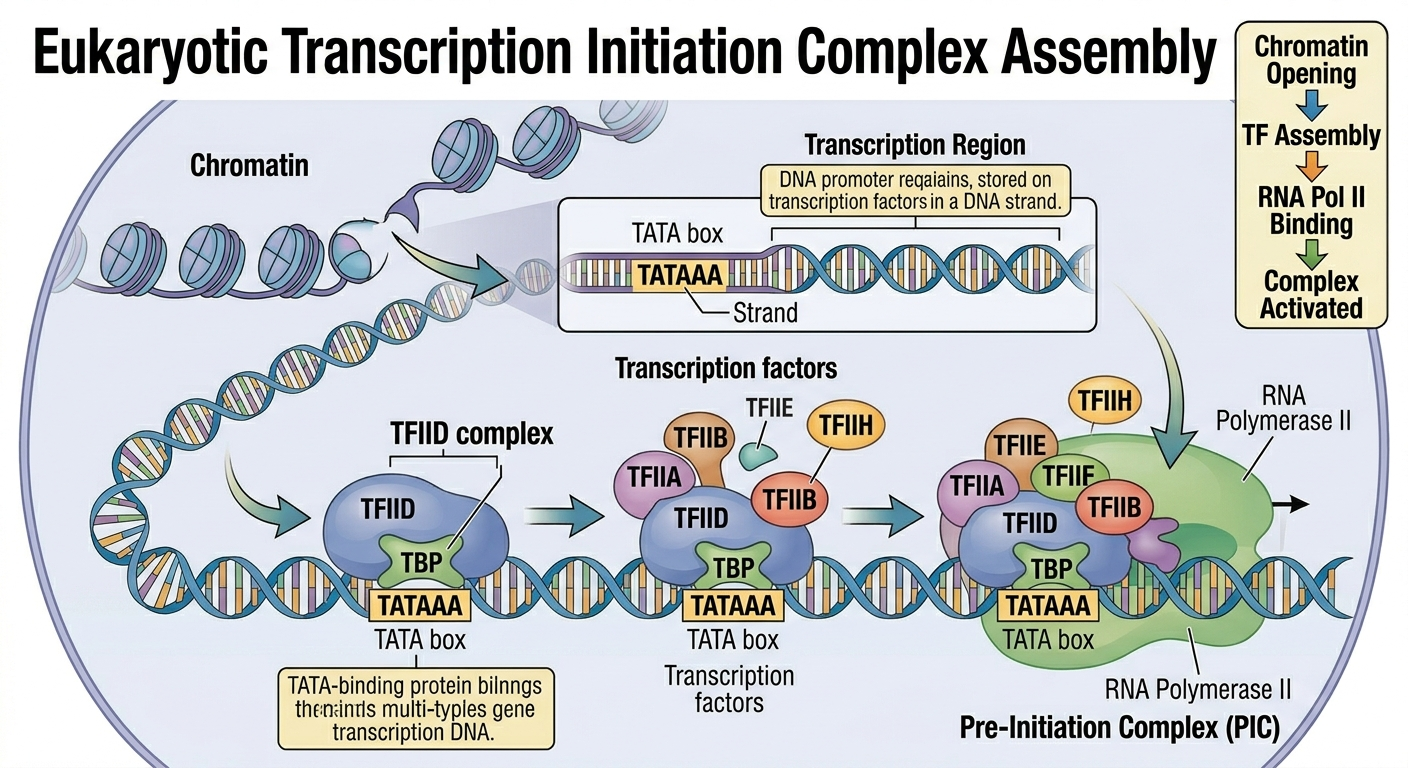
Figure 9. Eukaryotic transcription requires assembly of transcription factors and RNA polymerase II at the promoter.
The Primary Transcript
The initial RNA molecule synthesized by RNA polymerase II is known as the primary transcript. The primary transcript contains both coding and noncoding regions. The coding regions are known as exons because they remain in the mature RNA that exits the nucleus, while the noncoding regions are known as introns. Before the RNA can function as mRNA, the introns must be removed and the exons joined together in a process known as RNA processing or post-transcriptional modification, eventually becoming the mature mRNA.
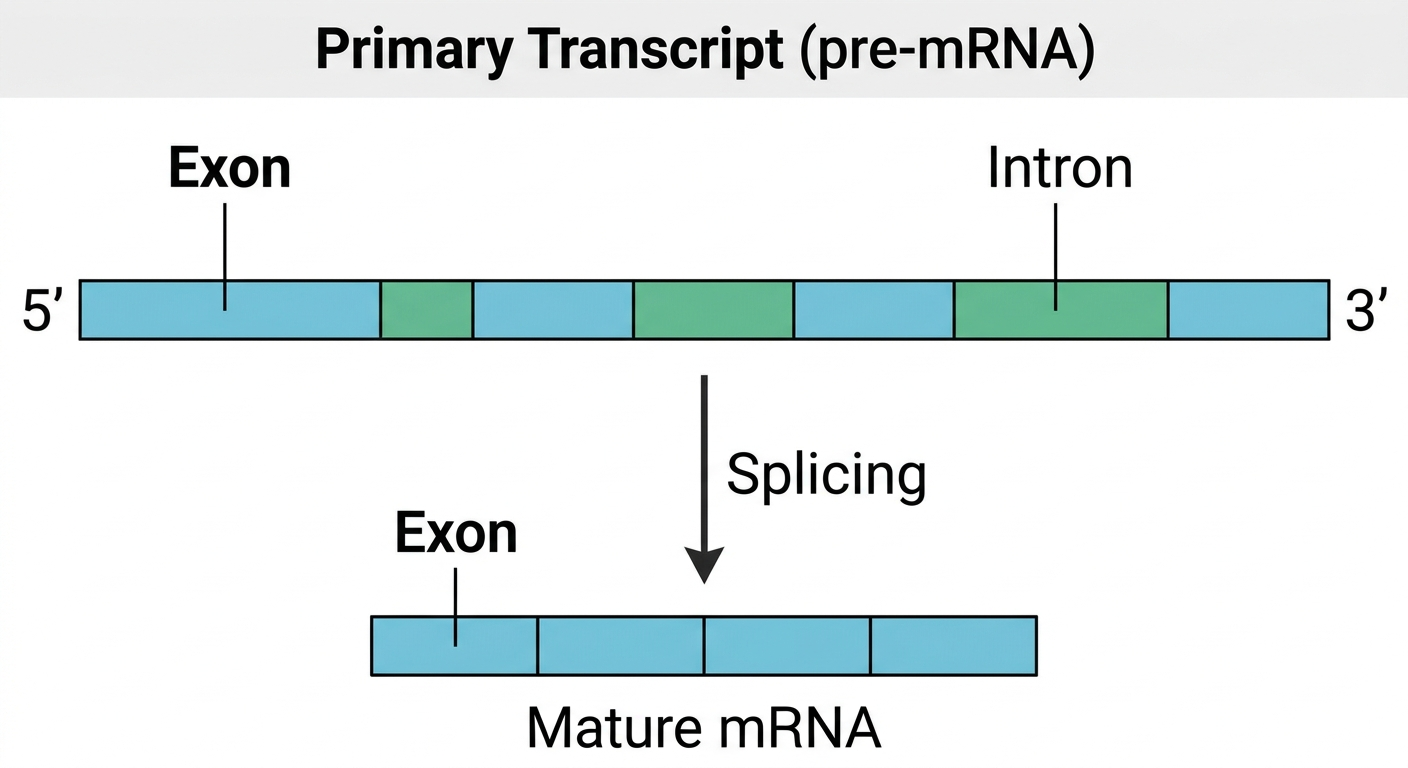
Figure 10. The primary transcript contains both coding exons and noncoding introns.
RNA Processing in Eukaryotes
The eukaryotic primary transcript undergoes several major modifications before leaving the nucleus. Soon after transcription begins, a modified guanine nucleotide is attached to the 5’ end of the primary transcript forming the 5’ cap, which protects the RNA from degradation and helps ribosomes recognize the mRNA during translation. At the 3’ end of the pre-mRNA, a long series of adenine nucleotides known as the poly-A tail is added, increasing RNA stability and assisting with export of the mRNA from the nucleus. RNA splicing removes introns from the pre-mRNA and joins exons together. Splicing is carried out by a molecular complex known as the spliceosome, which consists of proteins and small nuclear RNAs organized into structures called small nuclear ribonucleoproteins, or snRNPs. Specific snRNPs recognize nucleotide sequences marking intron-exon boundaries, assemble into the spliceosome, cut the RNA at both ends of the intron, remove the intron as a looped lariat structure, and splice adjacent exons together generating mature mRNA.
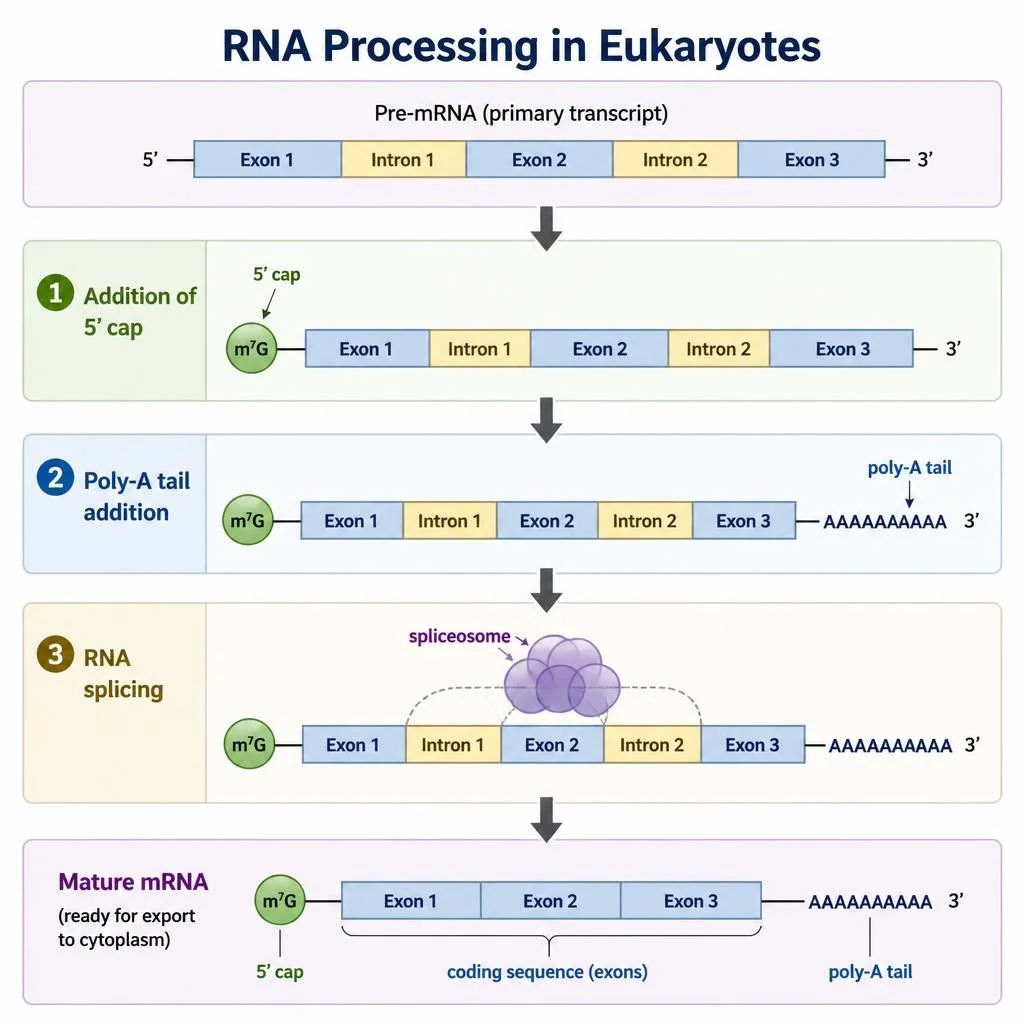
Figure 11. Formation of an RNA hairpin destabilizes transcription and causes termination in many bacterial genes.
Export of mRNA from the Nucleus
Once RNA processing is complete, mature mRNA exits the nucleus through structures known as nuclear pores and enters the cytoplasm attaching to a ribosome in order to carry out translation. In bacteria, transcription and translation occur simultaneously because bacteria lack a nucleus. In eukaryotes, however, transcription and translation are physically separated because transcription occurs inside the nucleus while translation occurs in the cytoplasm.
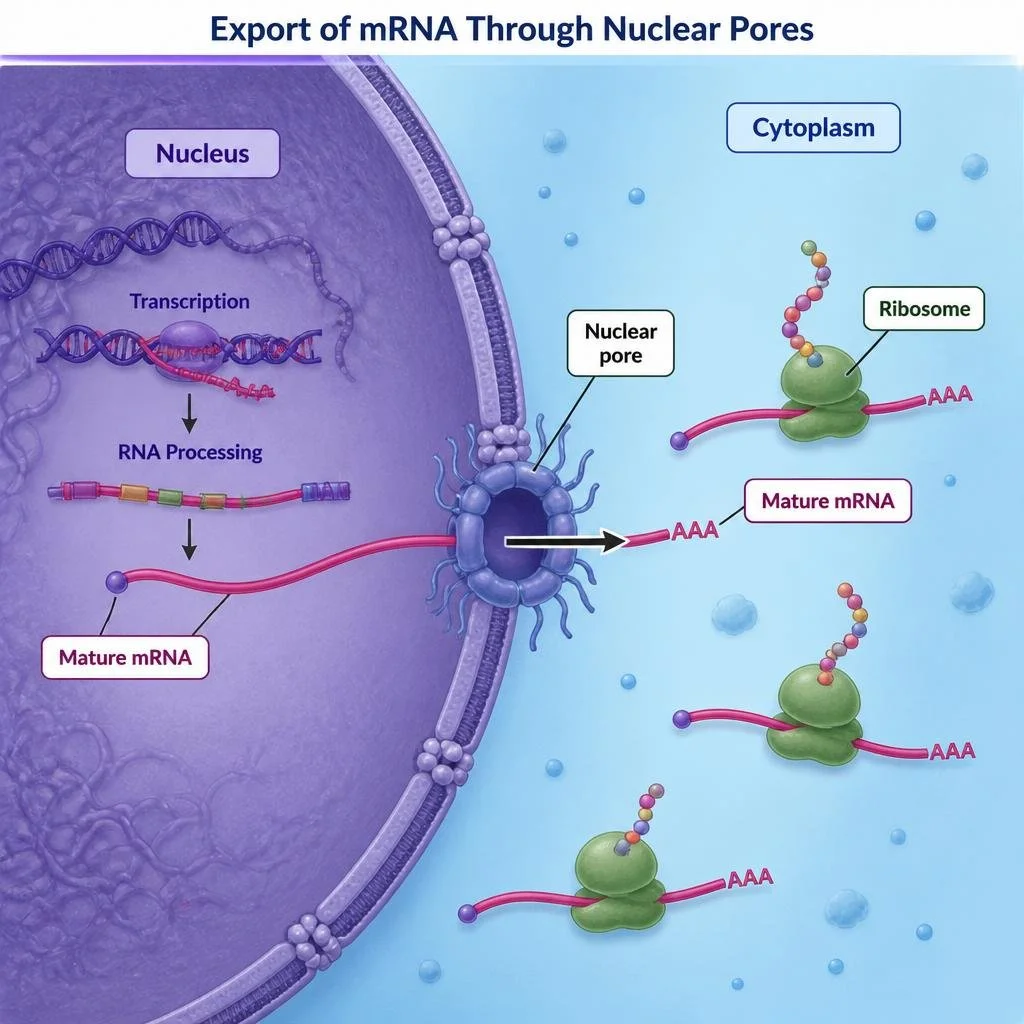
Figure 12. Processed mRNA exits the nucleus through nuclear pores before translation occurs in the cytoplasm.
Translation
Translation is the process by which the nucleotide sequence of mRNA is converted into the amino acid sequence of a protein. The genetic code is read in groups of three nucleotides known as codons, and each codon specifies a particular amino acid or translation signal. AUG codes for methionine and serves as the start codon, whereas UAA, UAG, and UGA function as stop codons. The sequence of codons within the mRNA determines the sequence of amino acids within the protein.
The Genetic Code
The genetic code is nearly universal among organisms, meaning most organisms use the same codons to specify the same amino acids. The near universality of the genetic code supports the idea that all organisms descended from a single common ancestor. Almost all life uses the same codons to specify the same amino acids, suggesting this coding system evolved once early in Earth’s history and was inherited by all descendants. If life had originated multiple independent times, scientists would expect major differences in the genetic code among organisms.
Because codons consist of three nucleotides and four different nucleotides exist, there are 64 possible codons that encode 20 amino acids and translation signals. The genetic code is redundant because multiple codons may specify the same amino acid. This redundancy helps reduce the effects of certain mutations.
The genetic code is unambiguous because each codon specifies only one amino acid or translation signal. For example, the codon UUU always codes for phenylalanine and does not code for any other amino acid.
The genetic code is highly conservative, meaning that nearly all organisms use the same codons to specify the same amino acids during protein synthesis. This conservation strongly suggests that the genetic code evolved early in the history of life and has been maintained through billions of years of evolution because of its essential role in cellular function.
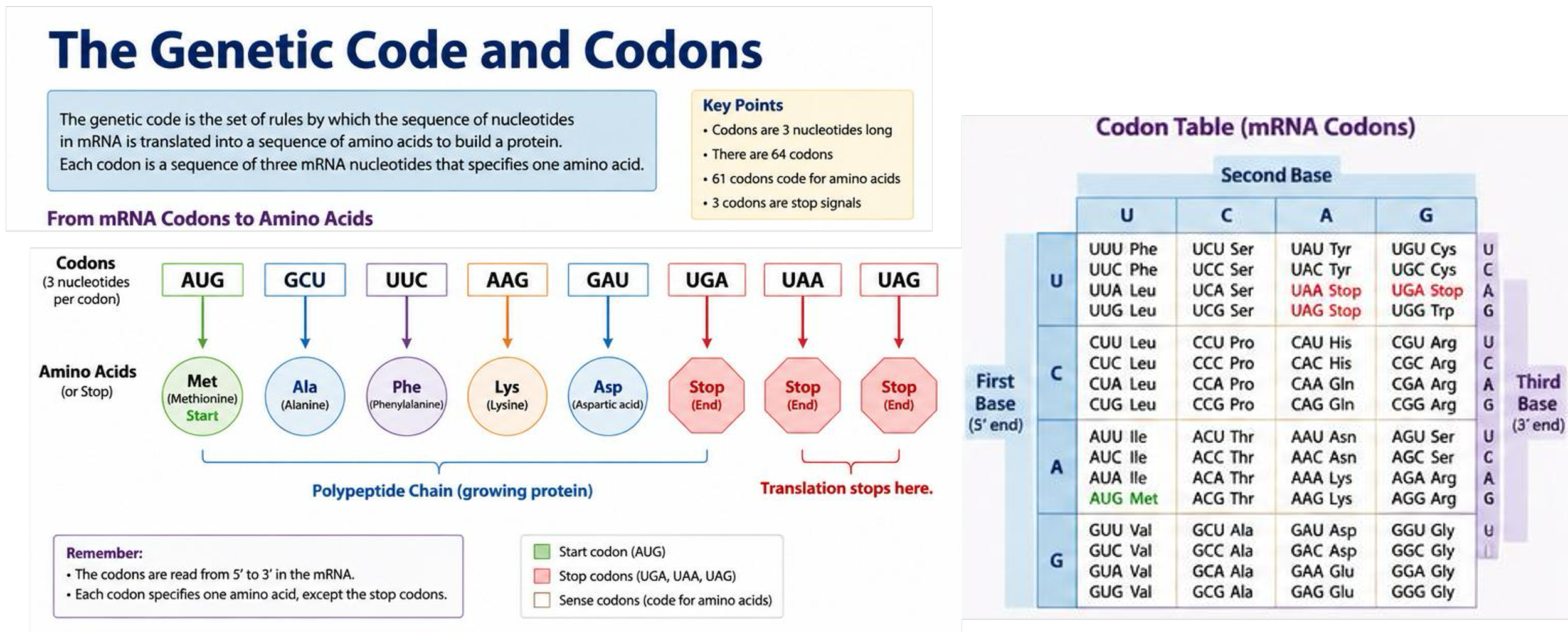
Figure 12. The genetic code translates mRNA codons into specific amino acids.
Transfer RNA
Transfer RNA, or tRNA, serves as the molecular bridge between mRNA codons and amino acids. Each tRNA molecule is attached to a specific amino acid, and at the opposite end of the tRNA is a three-nucleotide sequence known as the anticodon. The anticodon pairs with a complementary codon on the mRNA. Specialized enzymes known as aminoacyl-tRNA synthetases attach the correct amino acid to each tRNA molecule in a process known as charging. This process is essential because the ribosome itself does not verify whether the correct amino acid is attached.
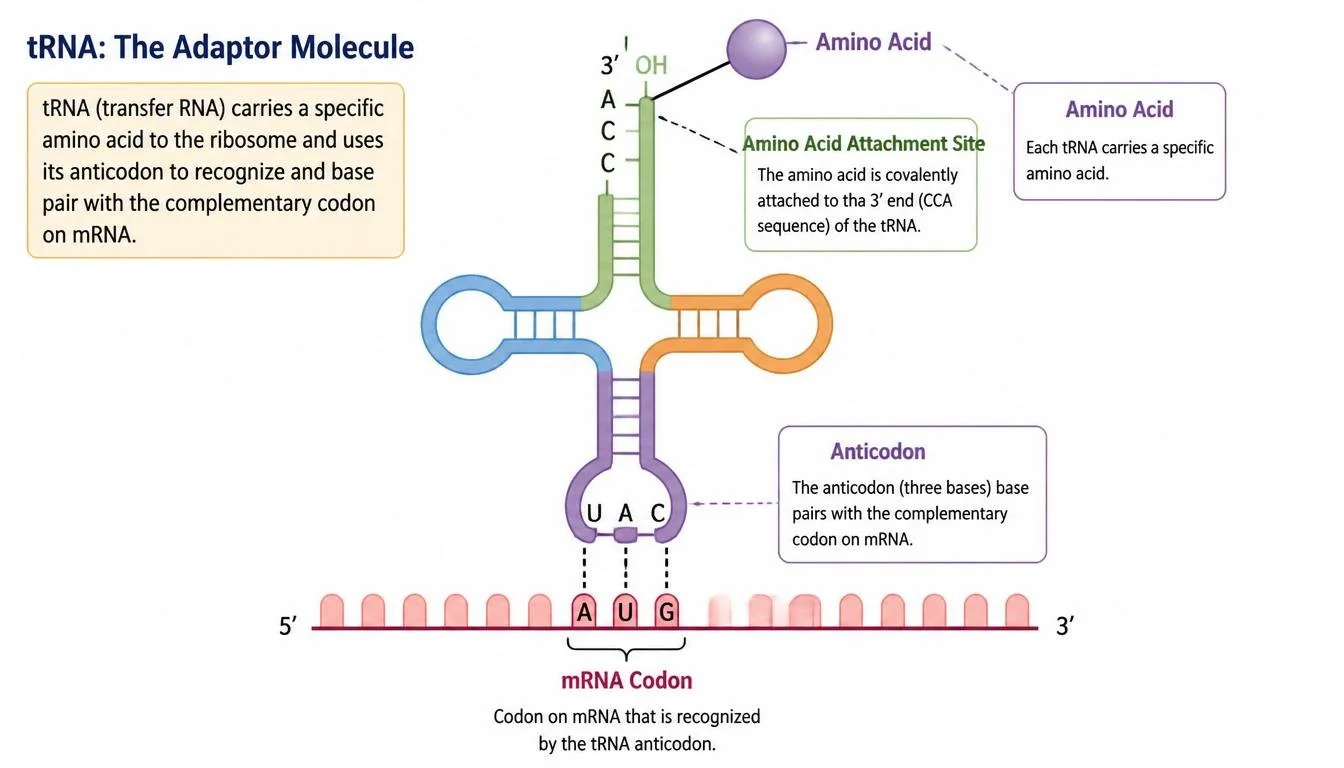
Figure 13. Transfer RNA carries amino acids and pairs anticodons with complementary mRNA codons.
Ribosomes
Ribosomes are the molecular machines responsible for protein synthesis. Ribosomes consist of ribosomal RNA and proteins organized into two subunits: a small subunit that binds the mRNA and a large subunit that catalyzes peptide bond formation between amino acids. Ribosomes contain three major binding sites. The A site, or aminoacyl site, receives incoming tRNAs. The P site, or peptidyl site, holds the growing polypeptide chain. The E site, or exit site, releases empty tRNAs from the ribosome. Remember the order as A-P-E.
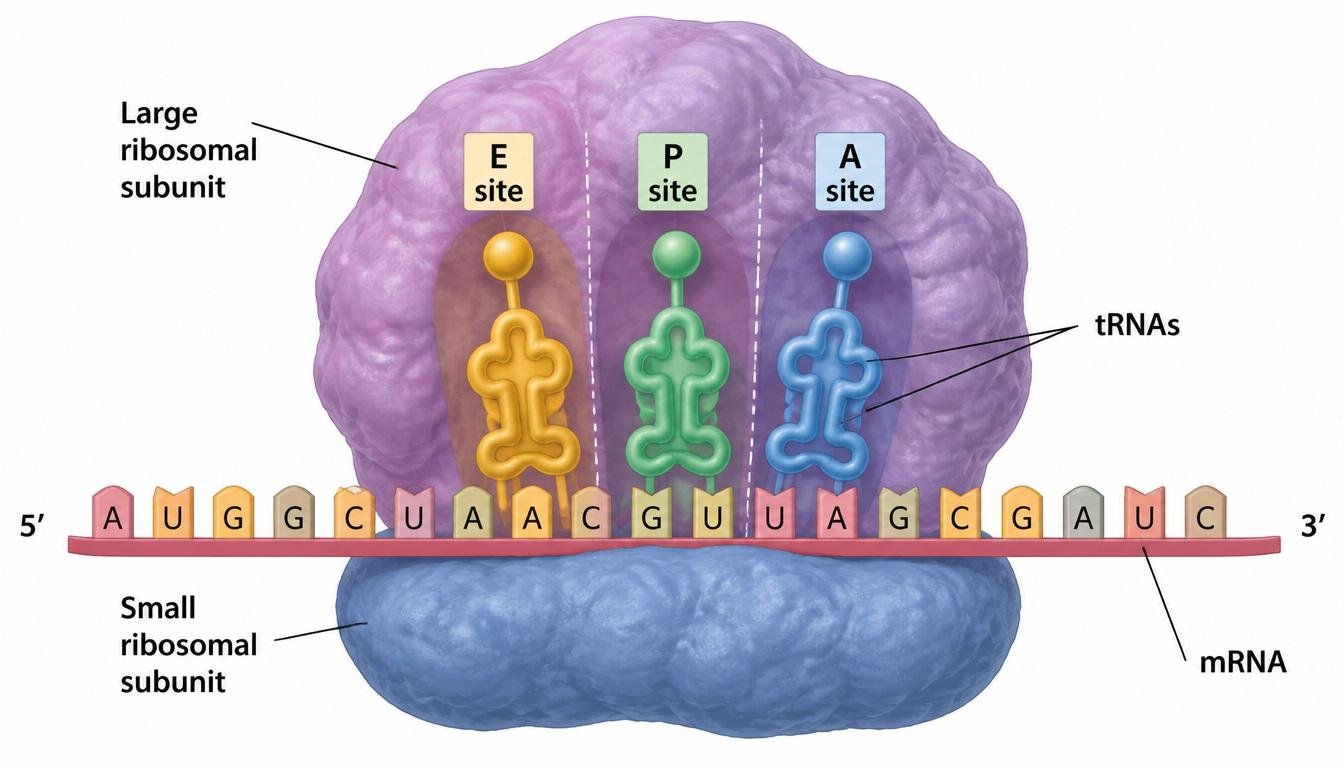
Figure 14. Ribosomes coordinate translation through specialized tRNA binding sites.
Initiation of Translation
Translation begins when the small ribosomal subunit binds to the mRNA. In bacteria, the ribosome recognizes a ribosome-binding site known as the Shine-Dalgarno sequence, whereas in eukaryotes the small ribosomal subunit typically binds near the 5’ cap and scans along the mRNA until it reaches the start codon. The start codon is usually AUG. A specialized initiator tRNA carrying methionine binds to the start codon. Once the initiator tRNA is positioned correctly, the large ribosomal subunit attaches and the initiator tRNA begins in the P site, positioning translation for elongation.

Figure 15. Translation initiation differs between bacteria and eukaryotes but both position the ribosome at the start codon.
Elongation of Translation
During elongation, amino acids are added one by one to the growing polypeptide chain. First, a charged tRNA enters the A site and pairs its anticodon with the complementary mRNA codon. Next, the ribosome catalyzes formation of a peptide bond between the amino acid in the P site and the amino acid in the A site, transferring the growing polypeptide chain onto the tRNA in the A site. The ribosome then shifts forward by one codon in a process known as translocation. As the ribosome moves, the tRNA in the A site shifts to the P site, the empty tRNA in the P site shifts to the E site and exits the ribosome, and a new codon enters the A site. This cycle repeats until the entire protein has been synthesized.
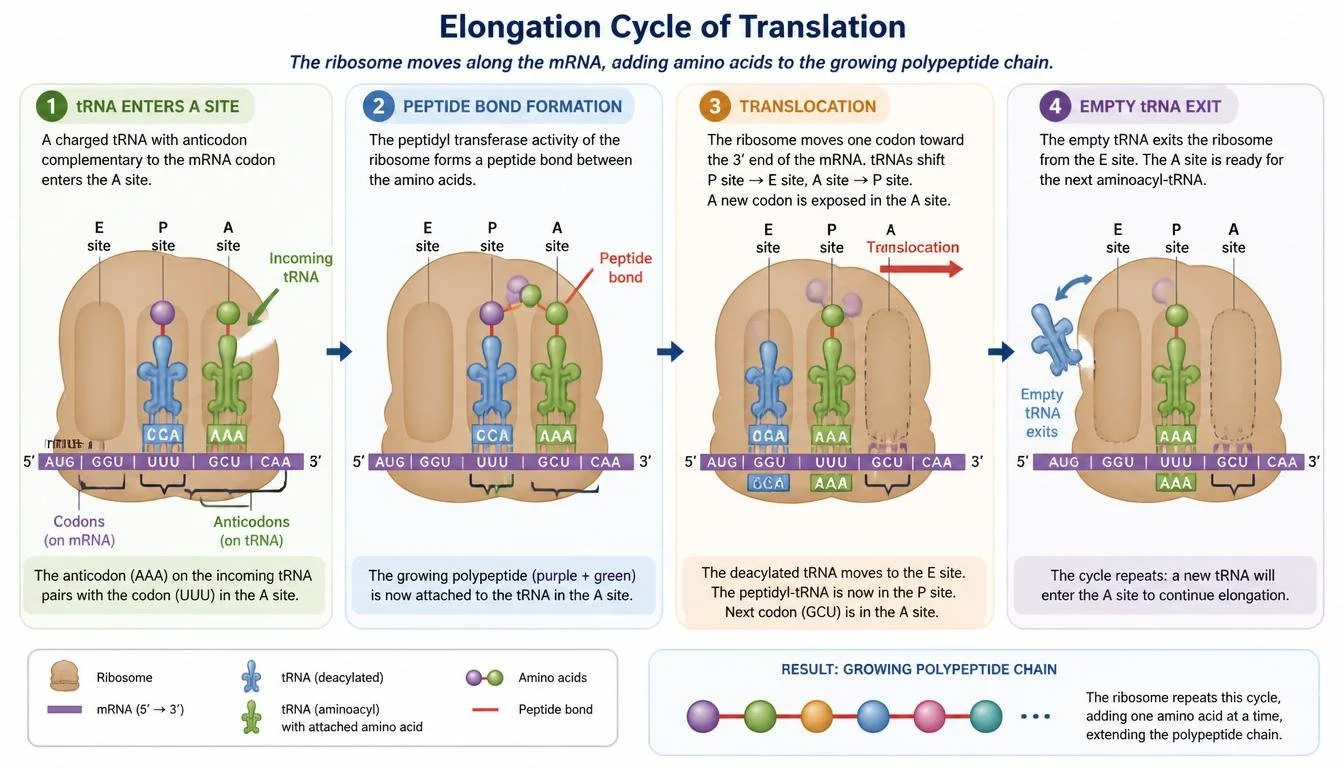
Figure 16. Translation elongation repeatedly adds amino acids to the growing polypeptide chain.
Termination of Translation
Translation ends when the ribosome encounters a stop codon. Stop codons do not code for amino acids and are not recognized by tRNAs. Instead, proteins known as release factors bind to the stop codon within the A site. Release factors trigger the release of the completed polypeptide chain from the ribosome, after which the ribosomal subunits separate and can participate in additional rounds of translation.
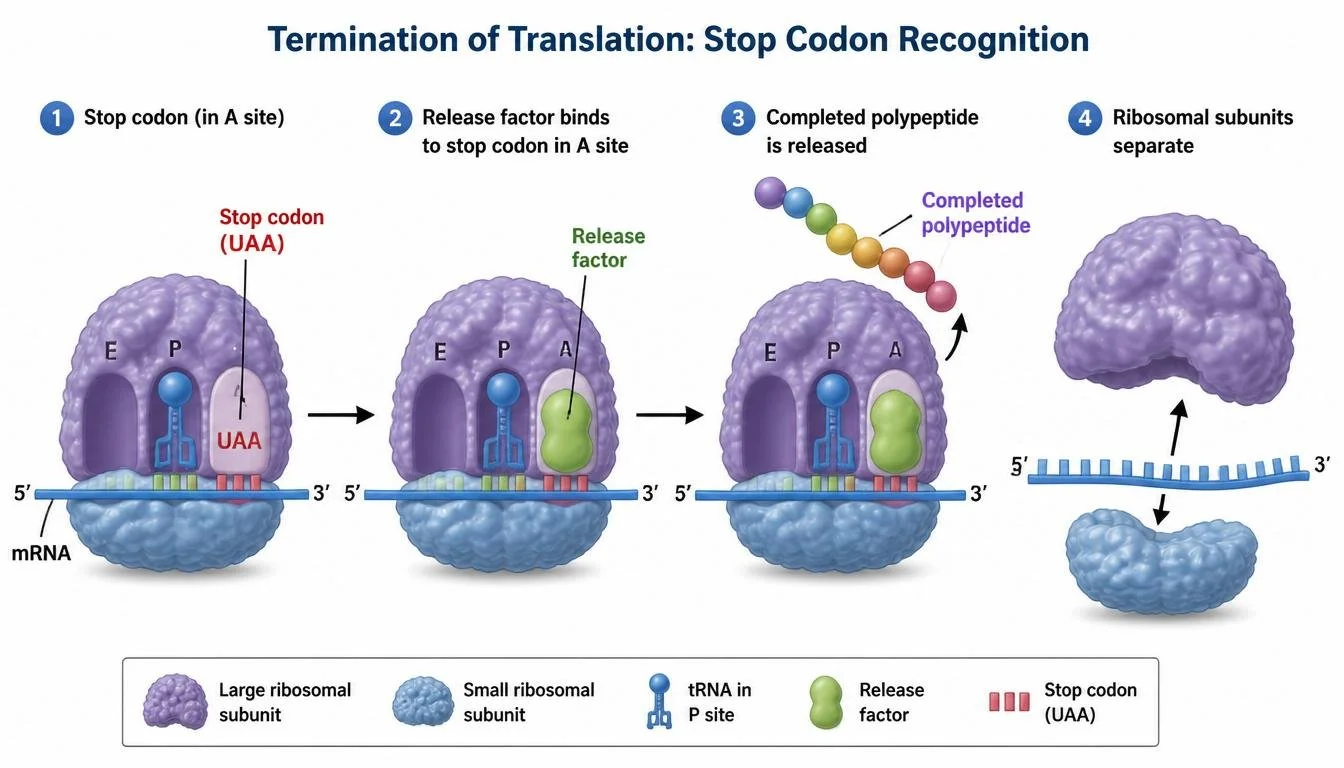
Figure 17. Release factors terminate translation when ribosomes encounter stop codons.
Coupled Transcription and Translation in Bacteria
Because bacteria lack a nucleus, transcription and translation can occur simultaneously. As RNA polymerase synthesizes mRNA, ribosomes immediately attach to the emerging transcript and begin translation. This allows bacterial cells to respond rapidly to environmental changes. In contrast, eukaryotic cells separate transcription and translation into different cellular compartments.
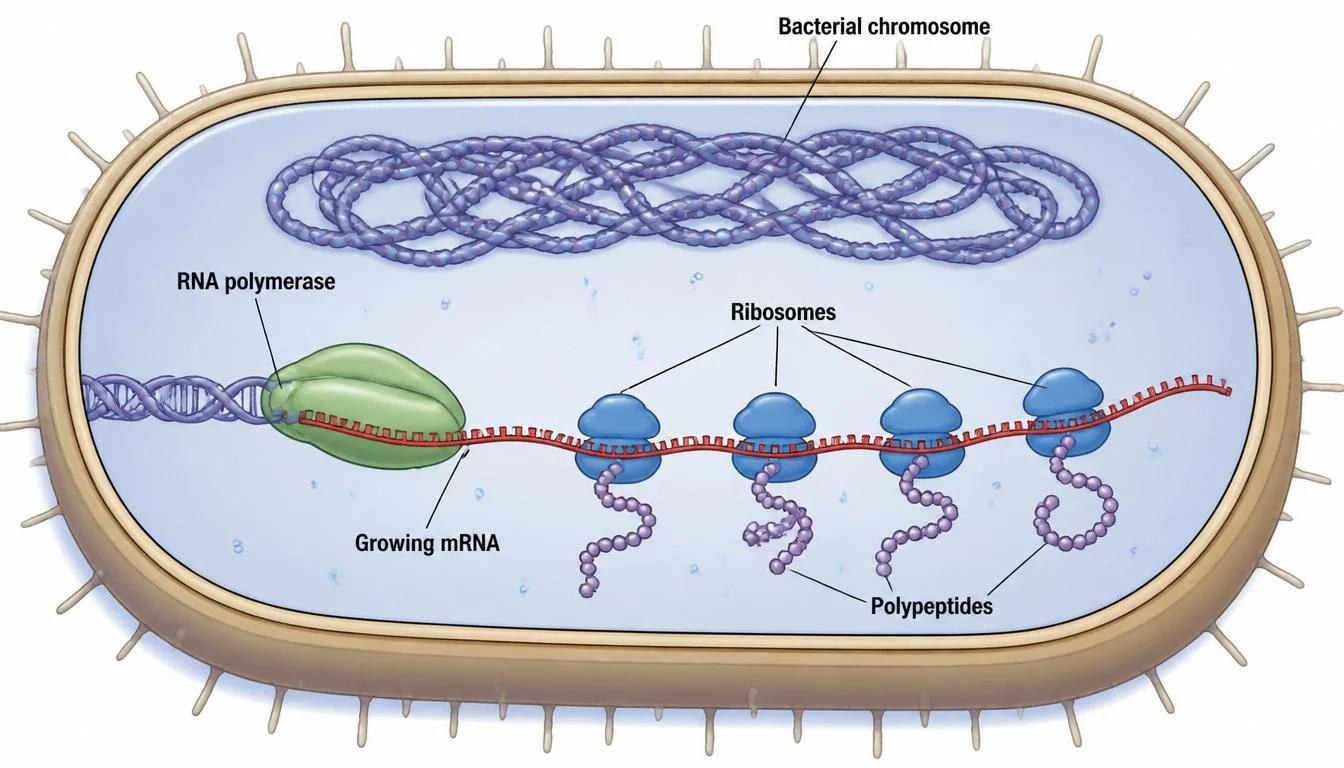
Figure 18. Because bacteria lack a nucleus, transcription and translation can occur simultaneously.
Decoupled Transcription and Translation in Eukaryontes
In contrast, eukaryotic cells separate transcription and translation into different cellular compartments. Transcription occurs inside the nucleus, where RNA polymerase synthesizes a pre-mRNA transcript from DNA. This RNA molecule is processed by the removal of introns through RNA splicing to produce mature mRNA. The mature mRNA then exits the nucleus through nuclear pores and enters the cytoplasm, where translation occurs on ribosomes either free in the cytoplasm or attached to the rough endoplasmic reticulum. This separation of transcription and translation allows eukaryotic cells to regulate gene expression more extensively through control of RNA processing, transport, stability, and translation.
Figure 19. In eukaryotes, transcription occurs in the nucleus while translation occurs in the cytoplasm.
Regulation of Gene Expression
Not all genes are active at all times. Cells carefully regulate transcription and translation to control which proteins are produced. Gene regulation allows cells with identical DNA to develop into different cell types. For example, muscle cells and neurons contain the same genome but express different sets of genes.
Gene Regulation and Prevention of HIV Infection
RNA splicing is part of how cells edit RNA after a gene is copied from DNA. During splicing, the cell can join or remove different RNA segments, which can change the final message used to build a protein. Some people that have been infected with HIV, can be essentially immune to the disease. In these people, RNA splicing removes the introns of the primary transcript (pre-mRNA) for an HIV protein (i.e. CCR5) This can reduce how much of the working receptor is made or produce a nonfunctional version. Since HIV needs CCR5 to enter immune cells, changes in splicing that lower or disrupt CCR5 production can make infection much more difficult.
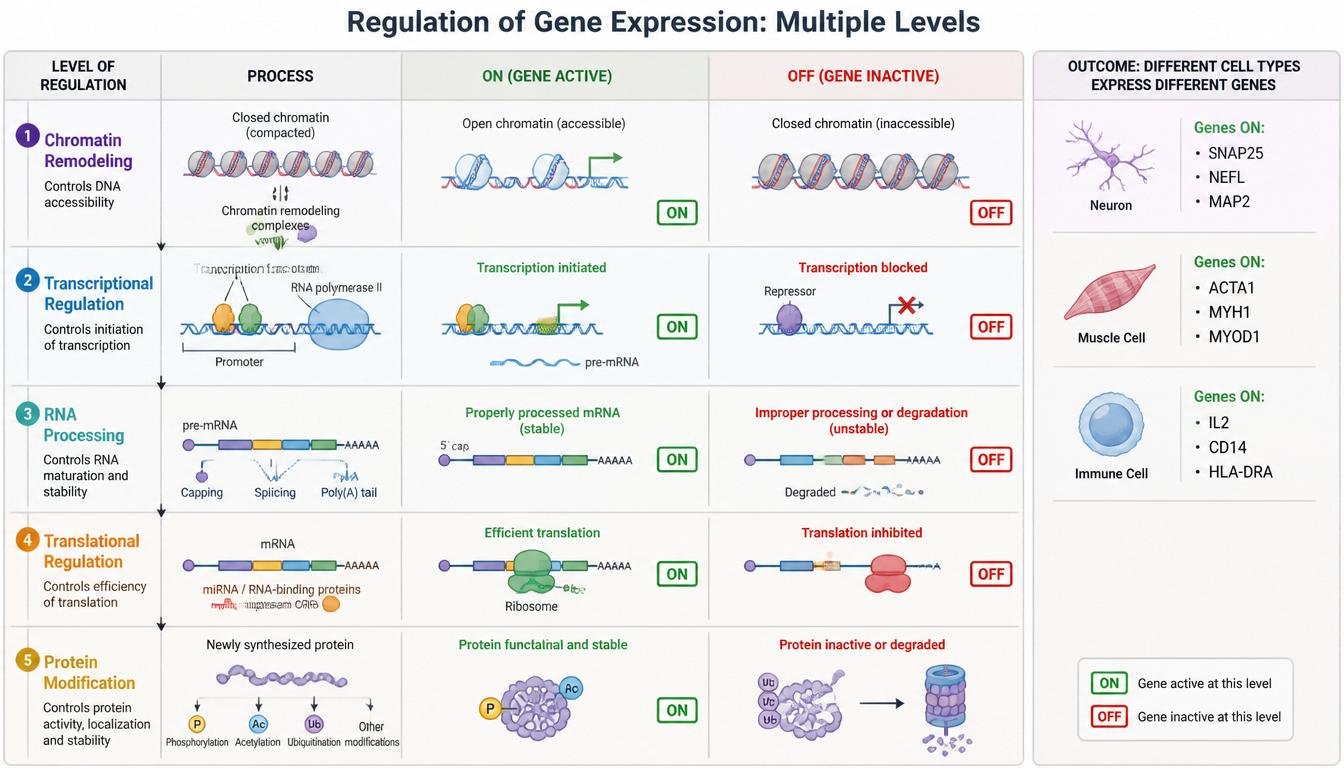
Figure 20. Gene expression can be regulated at multiple stages from chromatin structure to protein modification.
The Importance of Transcription and Translation
Transcription and translation are among the most fundamental processes in biology because together they convert genetic information stored in DNA into the proteins responsible for cellular structure and function. Every enzyme, structural protein, transport protein, receptor, and signaling molecule ultimately depends upon accurate gene expression. Understanding transcription, RNA processing, and translation is central to modern genetics, biotechnology, medicine, and molecular biology. Many diseases result from disruptions in these processes including cancer, genetic disorders, and viral infections. Modern technologies such as recombinant DNA engineering, CRISPR gene editing, RNA vaccines, and synthetic biology all rely heavily on our understanding of how genetic information flows from DNA to RNA to protein.
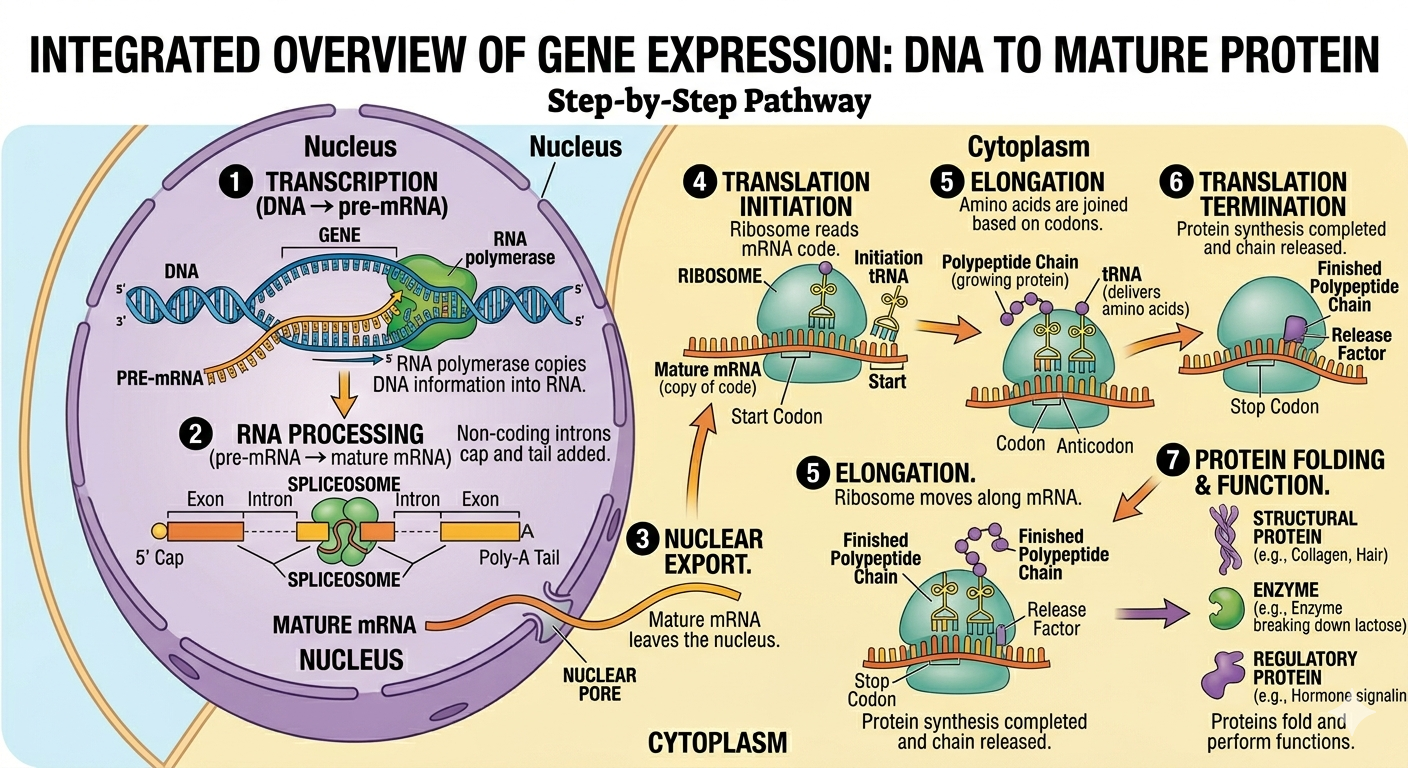
Figure 21. Gene expression converts information stored in DNA into functional proteins through transcription, RNA processing, and translation.