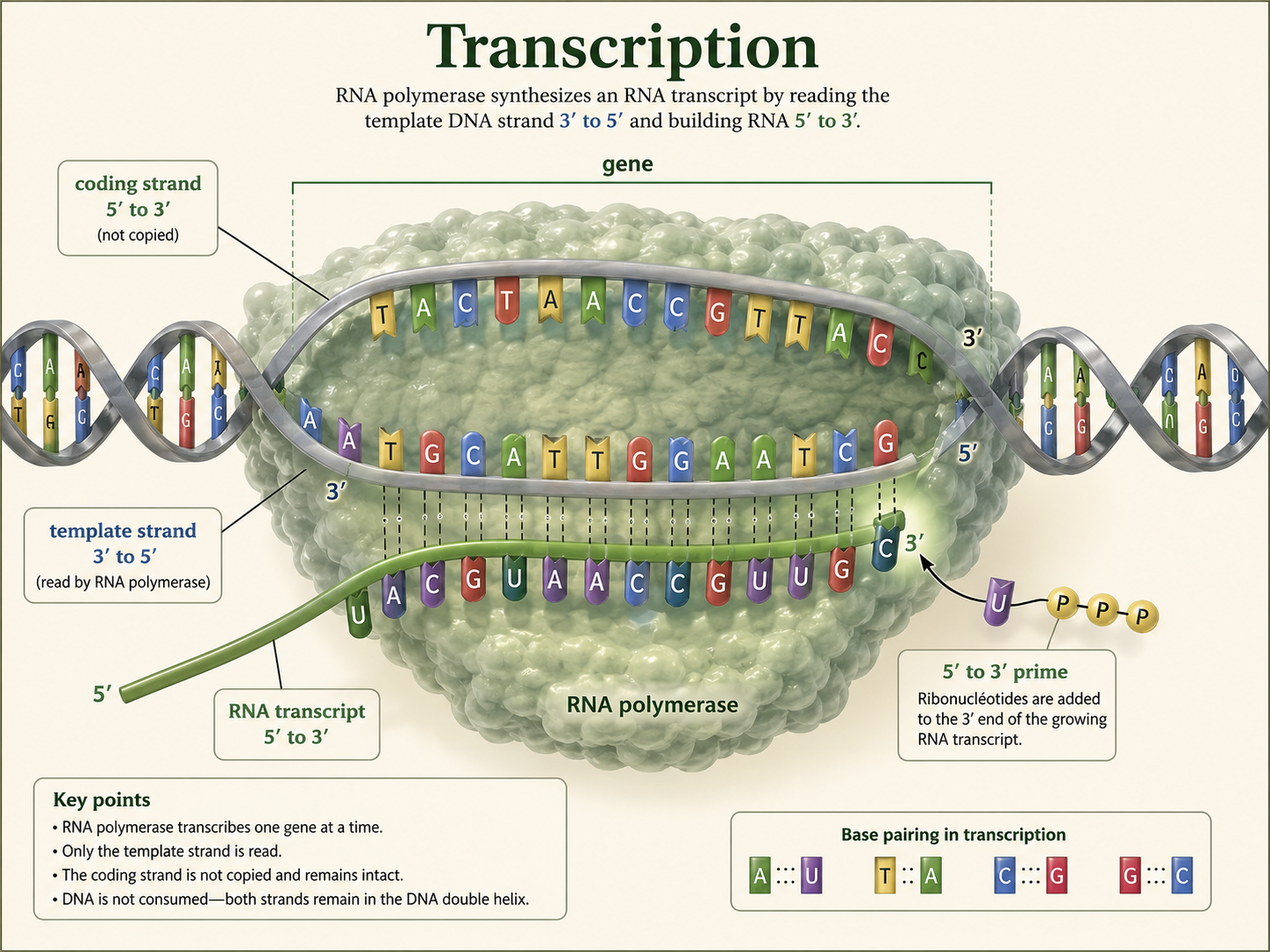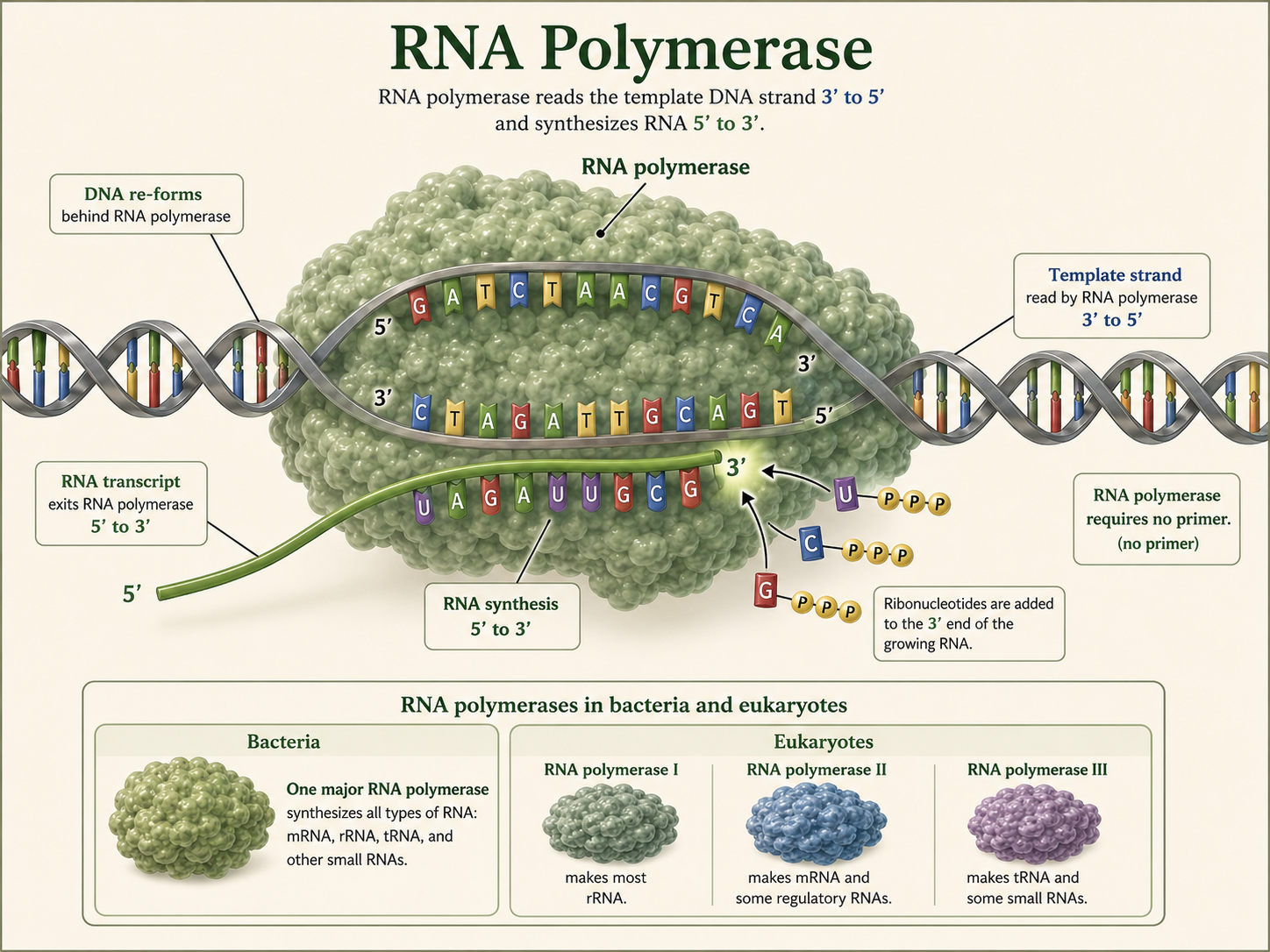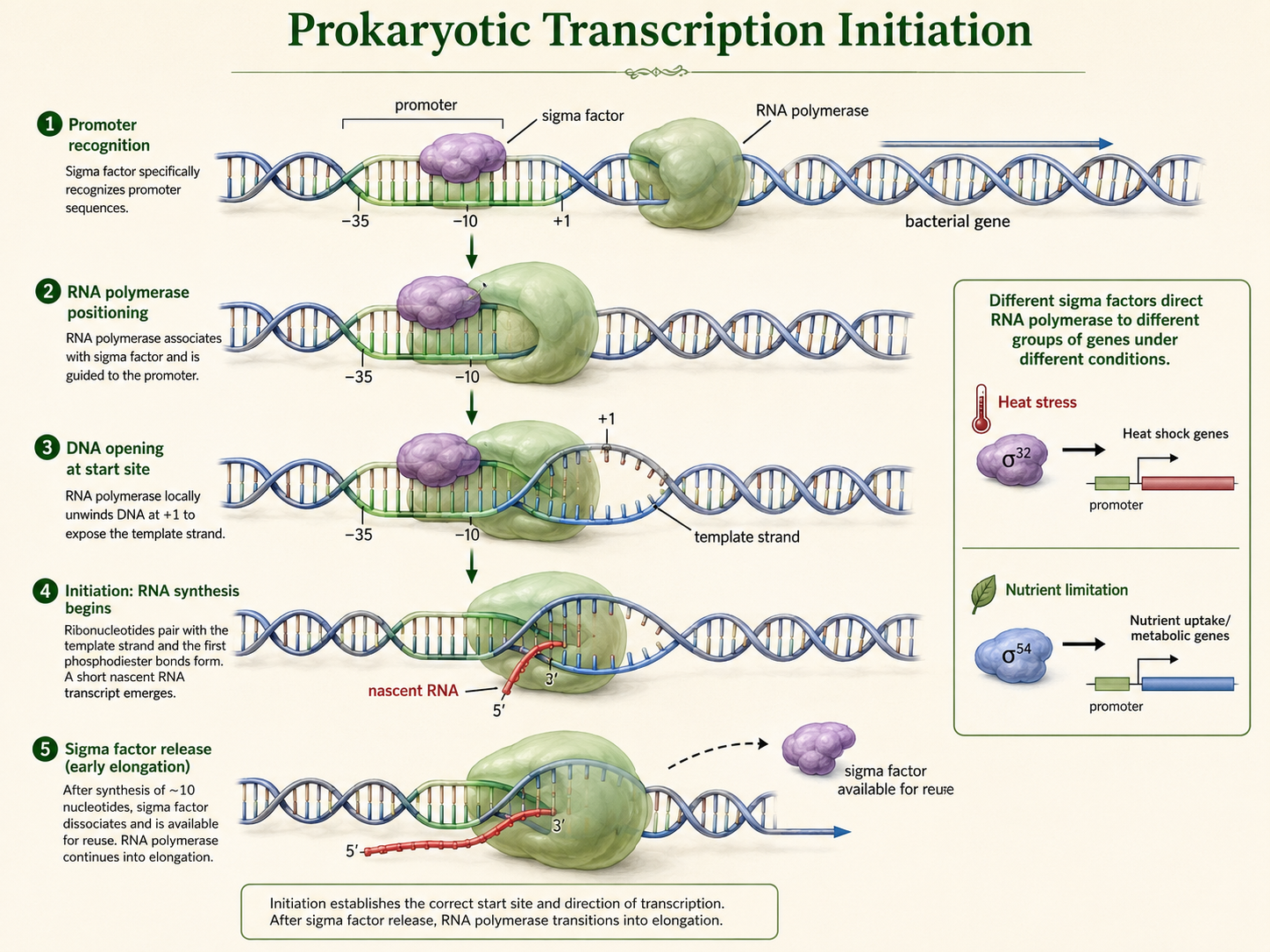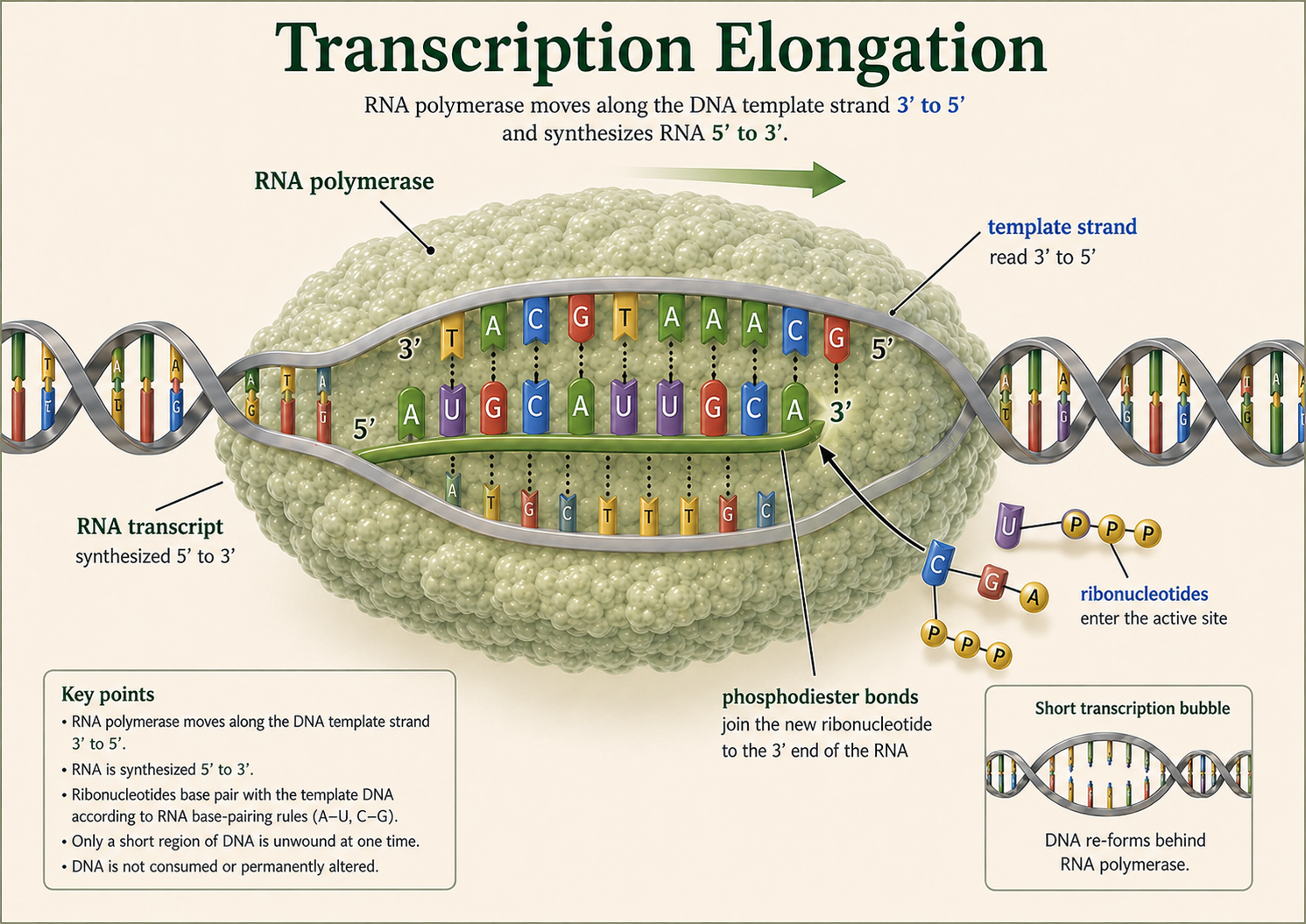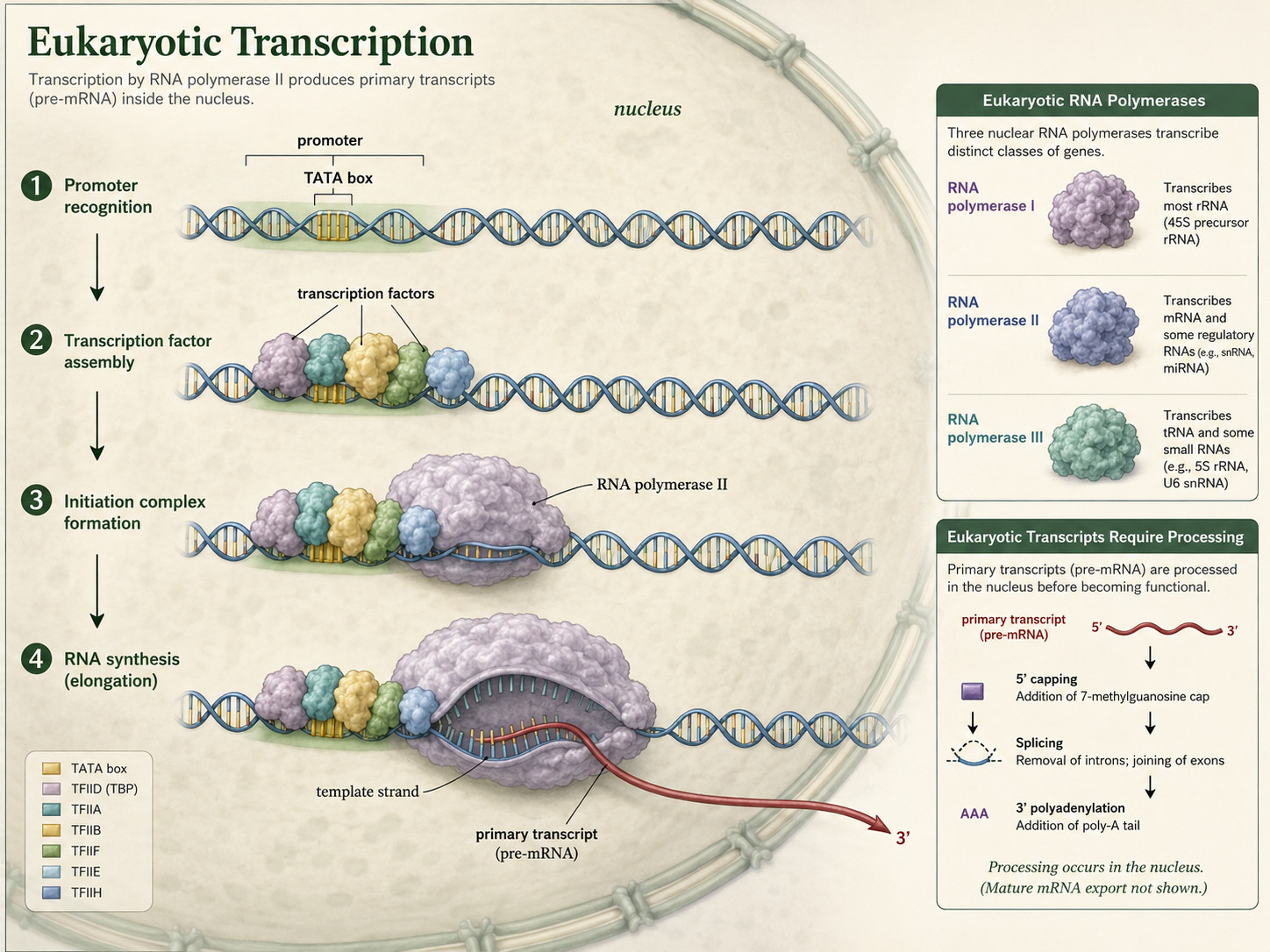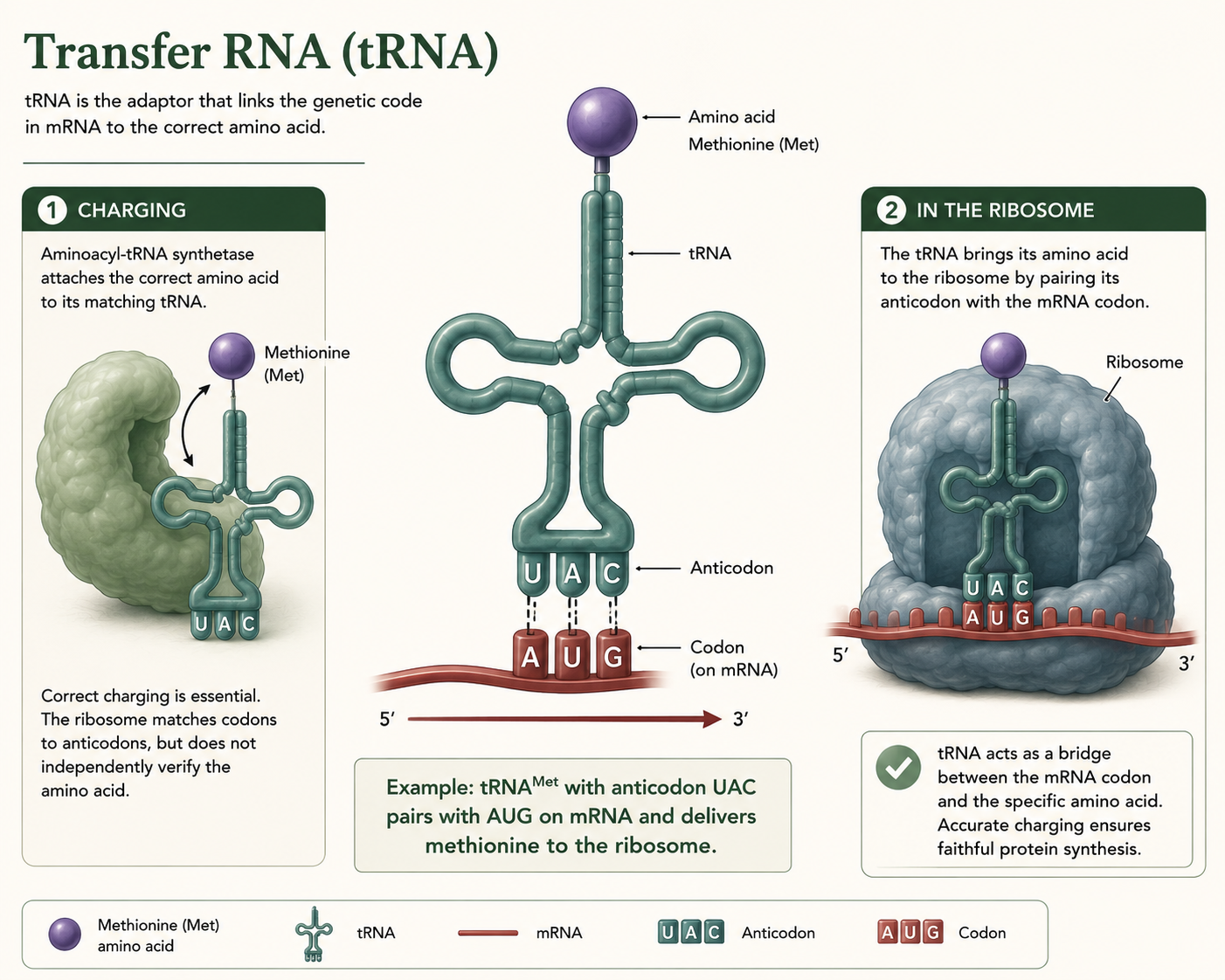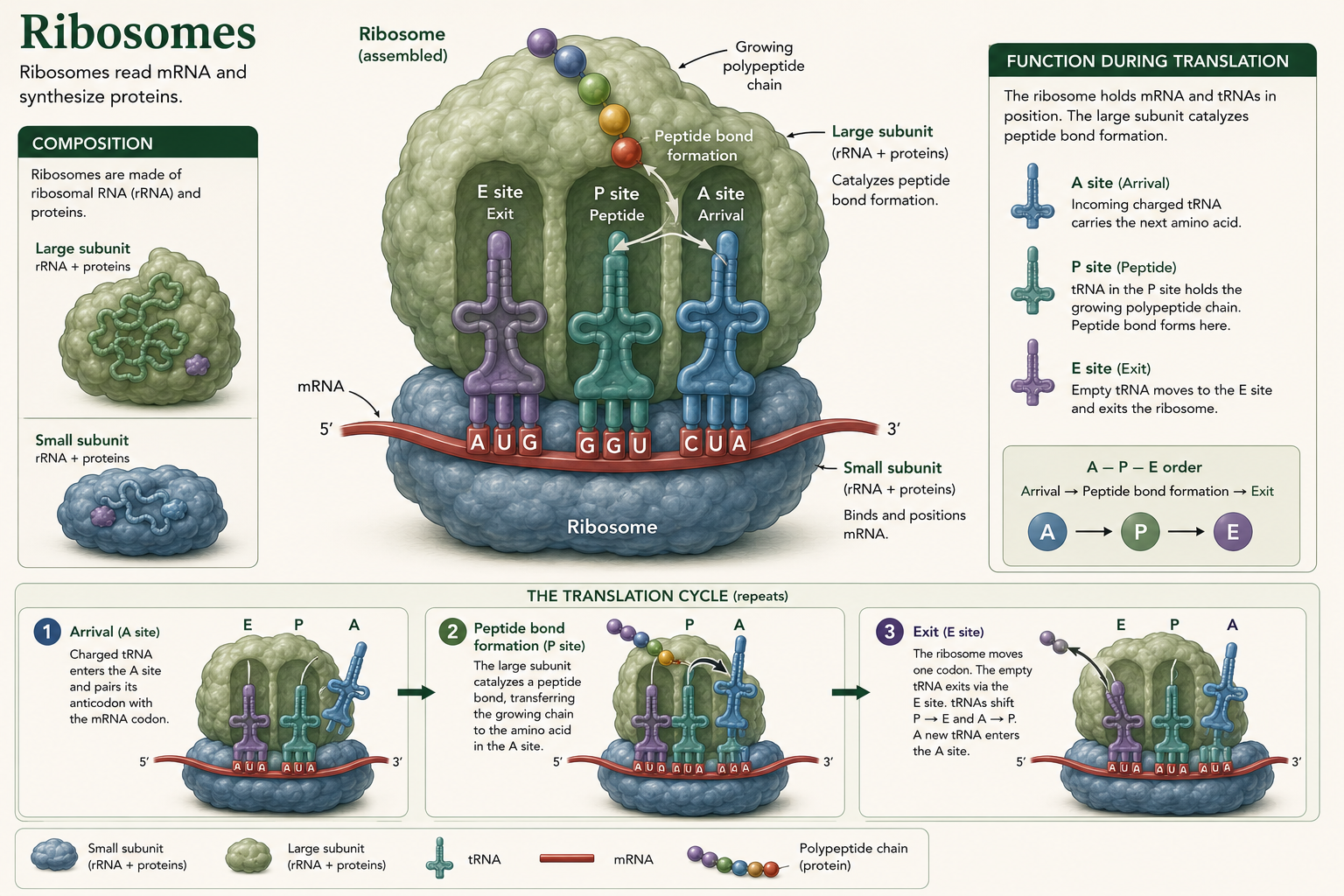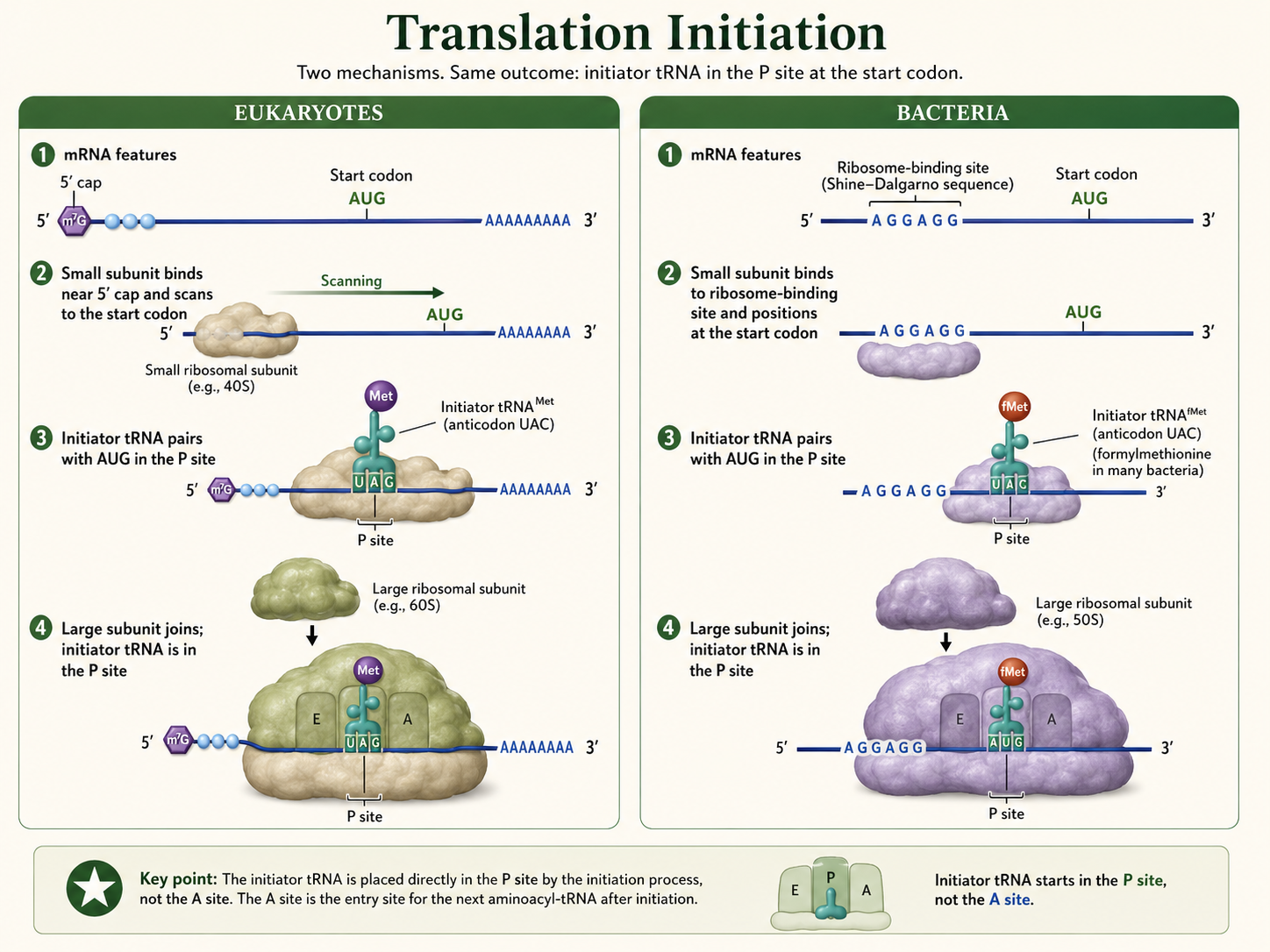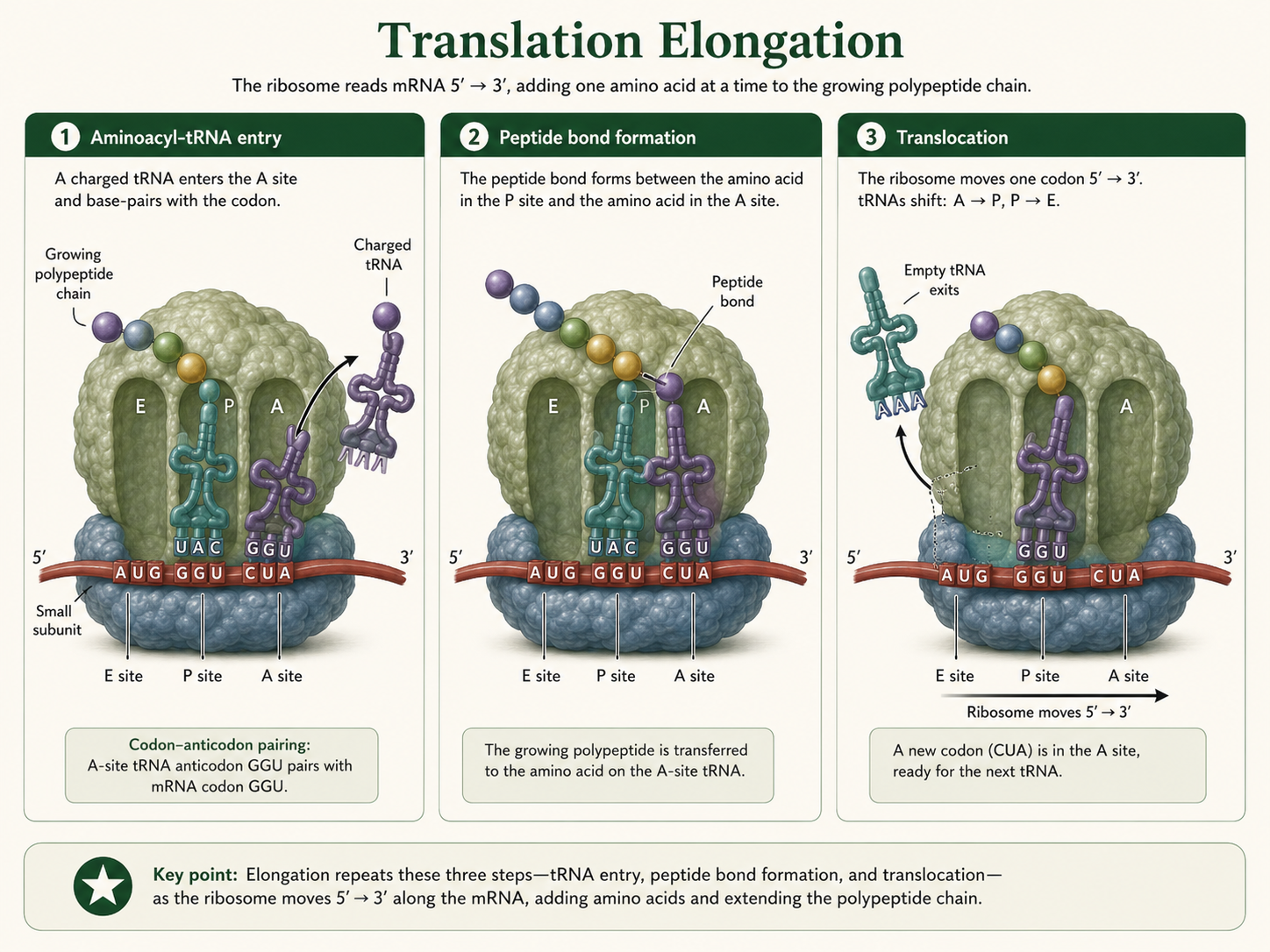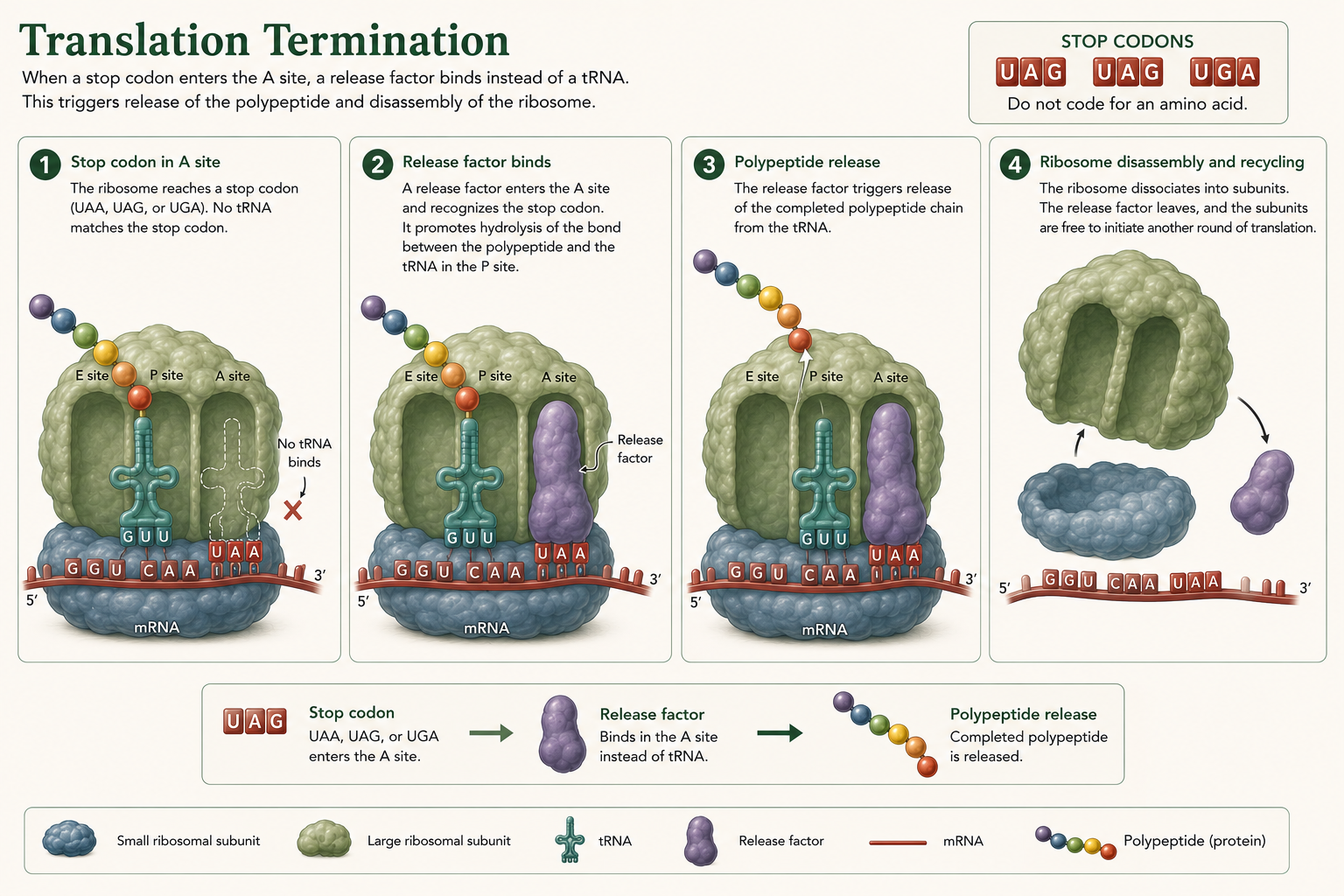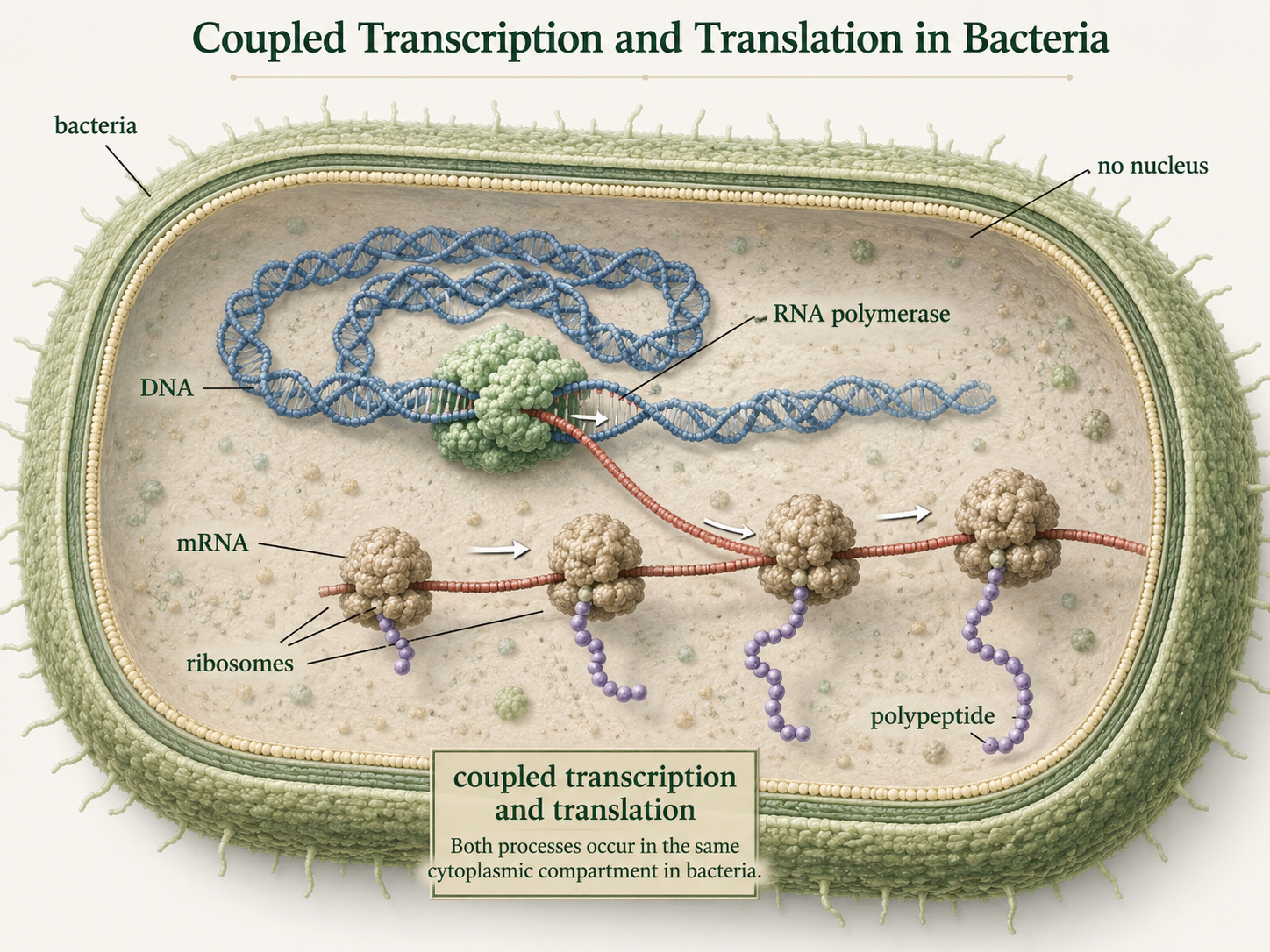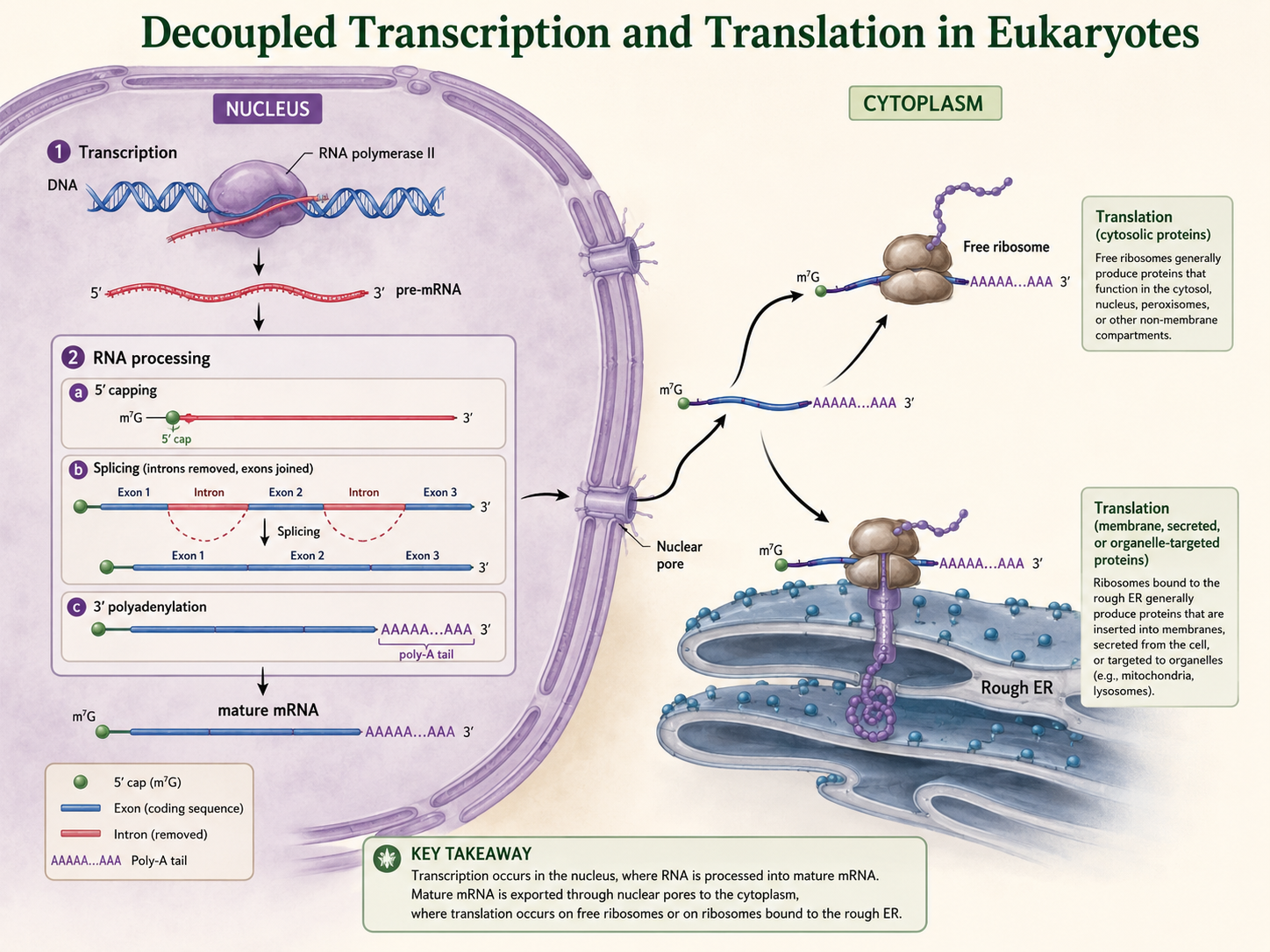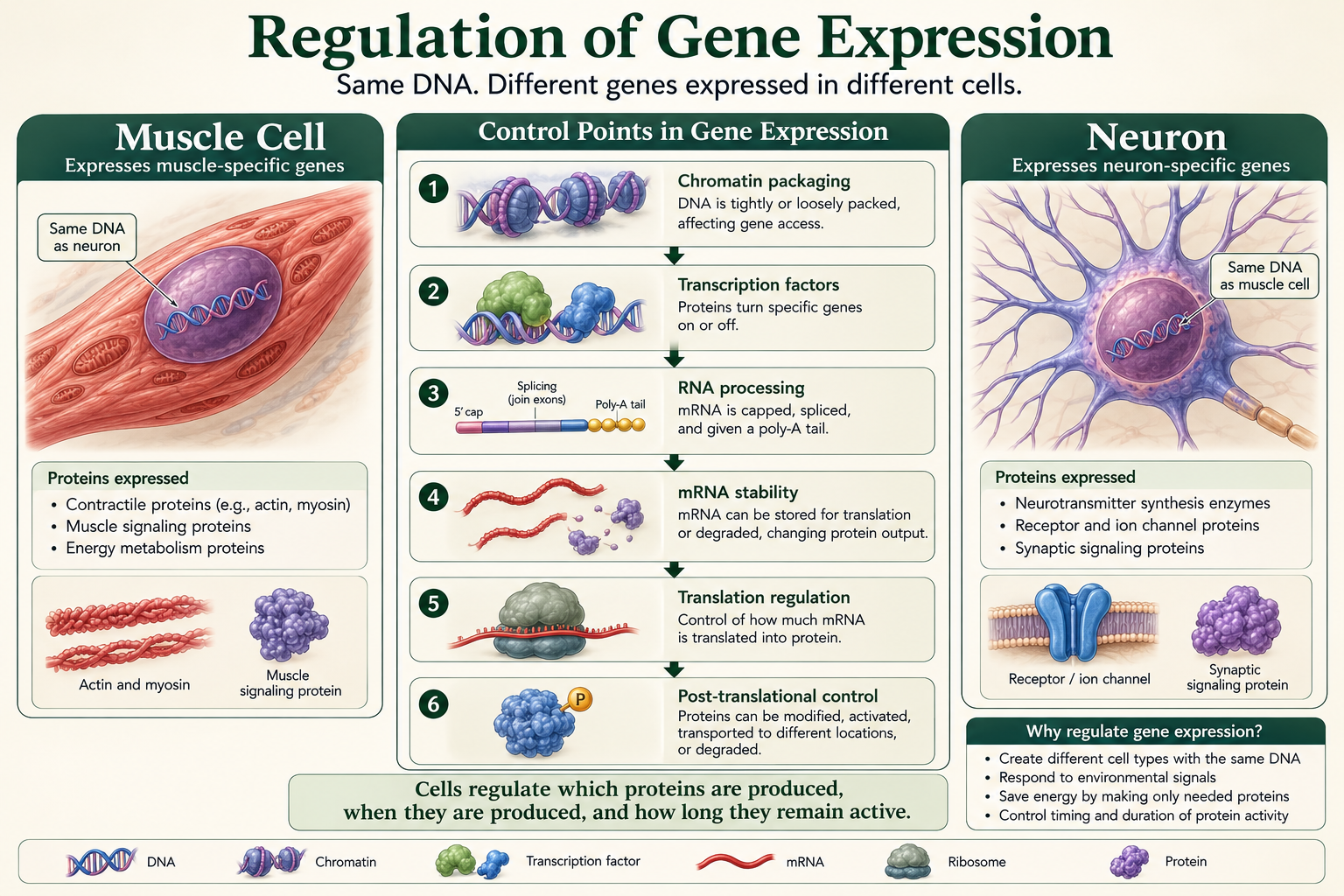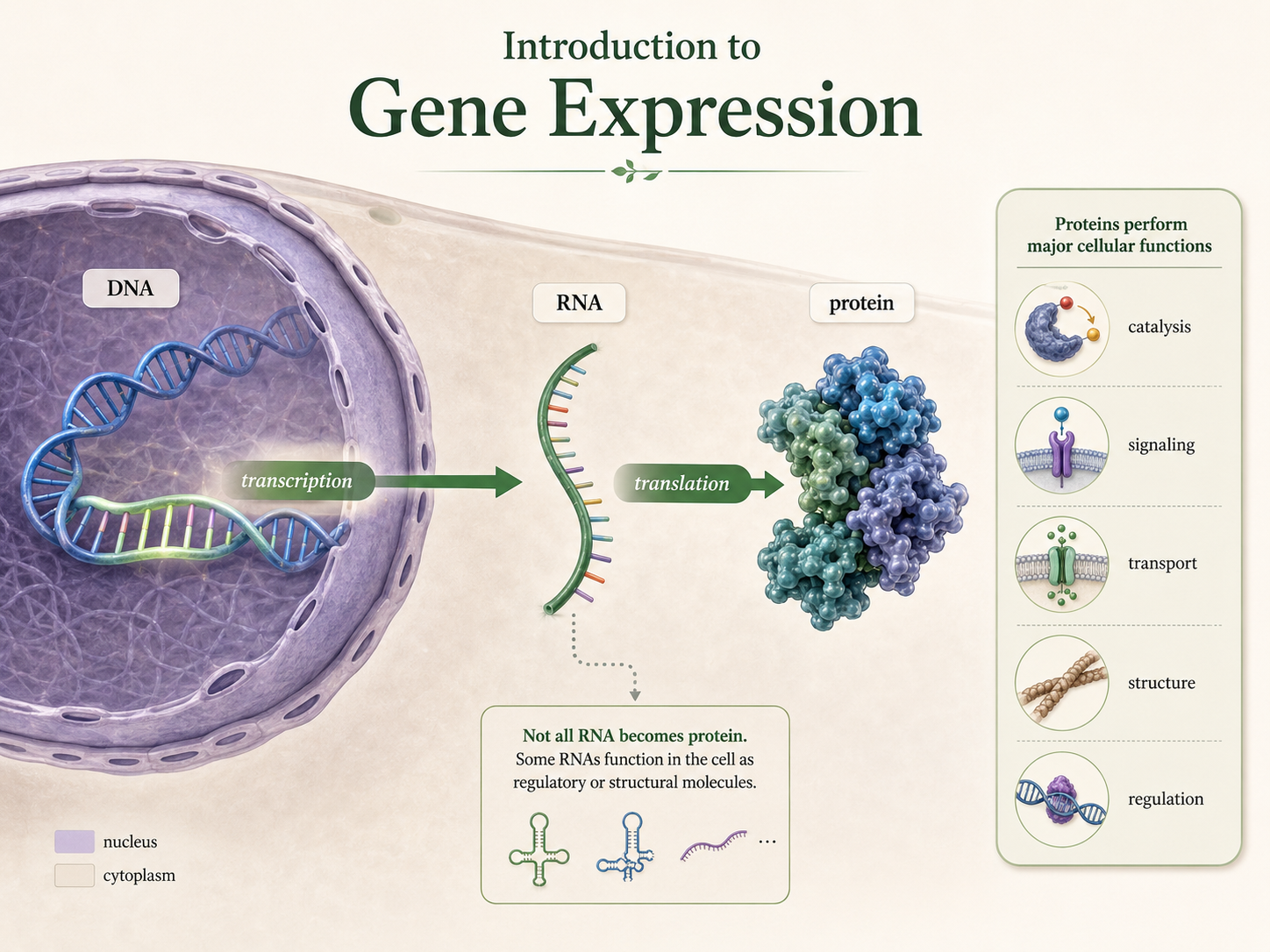
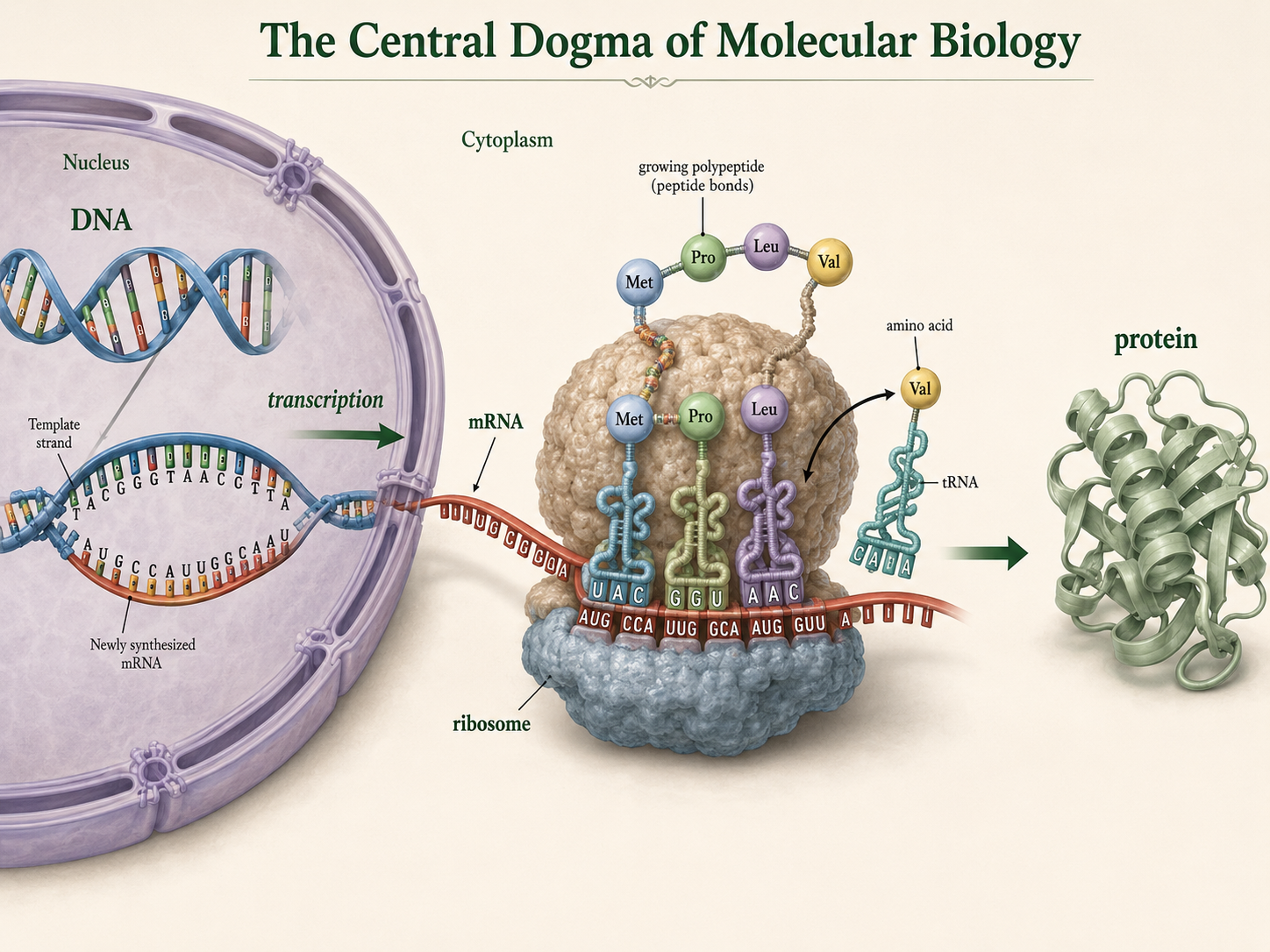
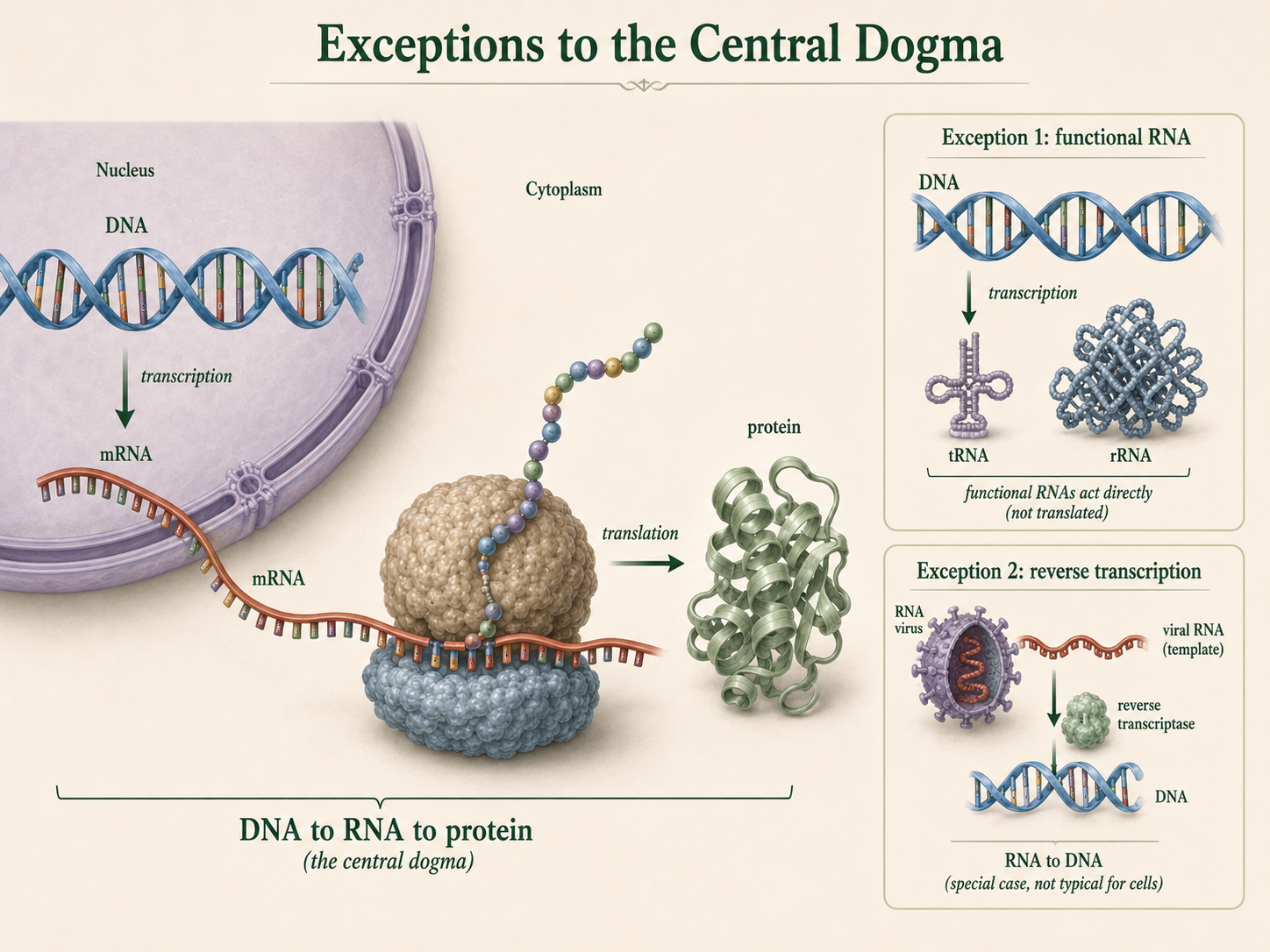
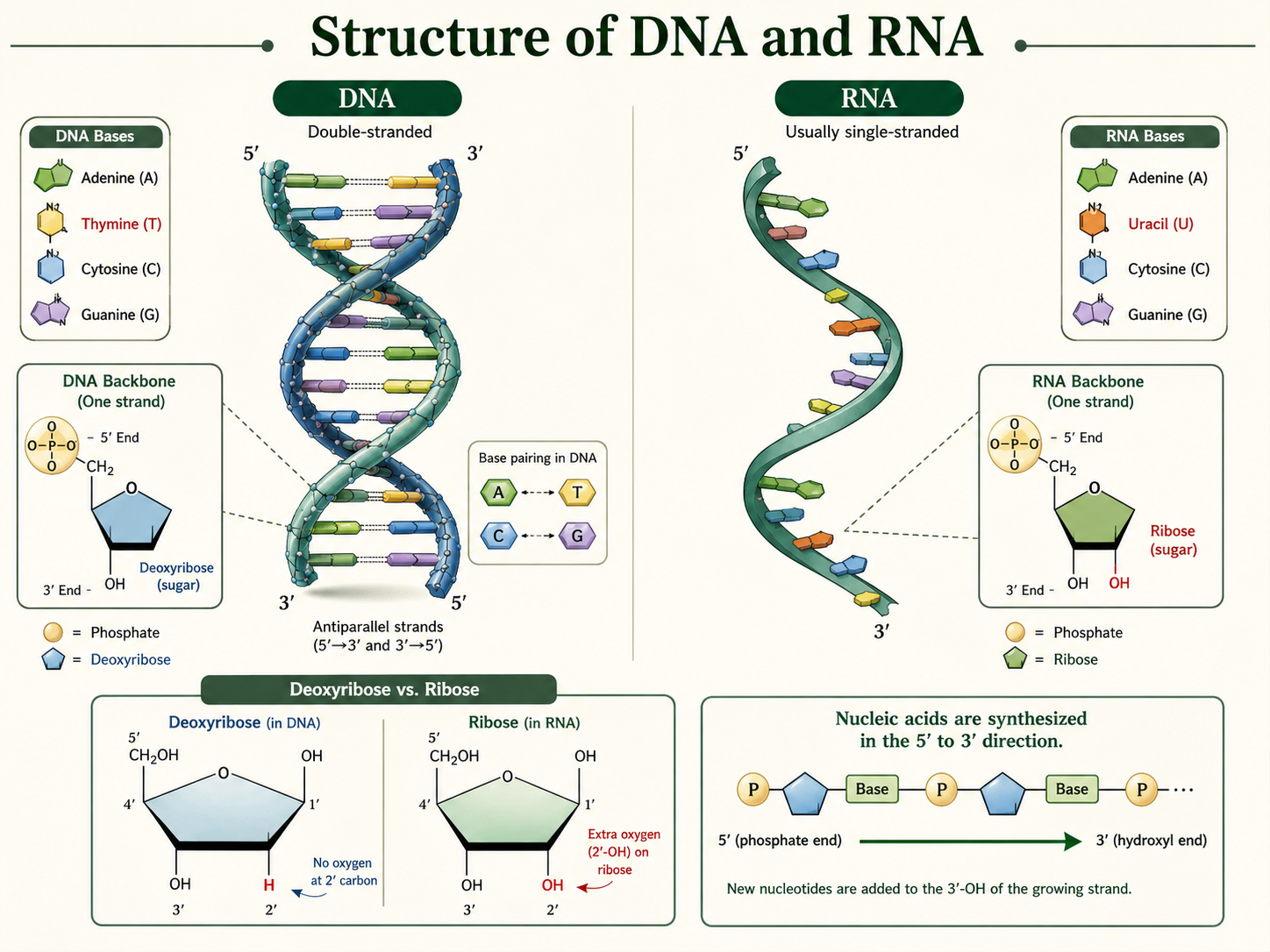

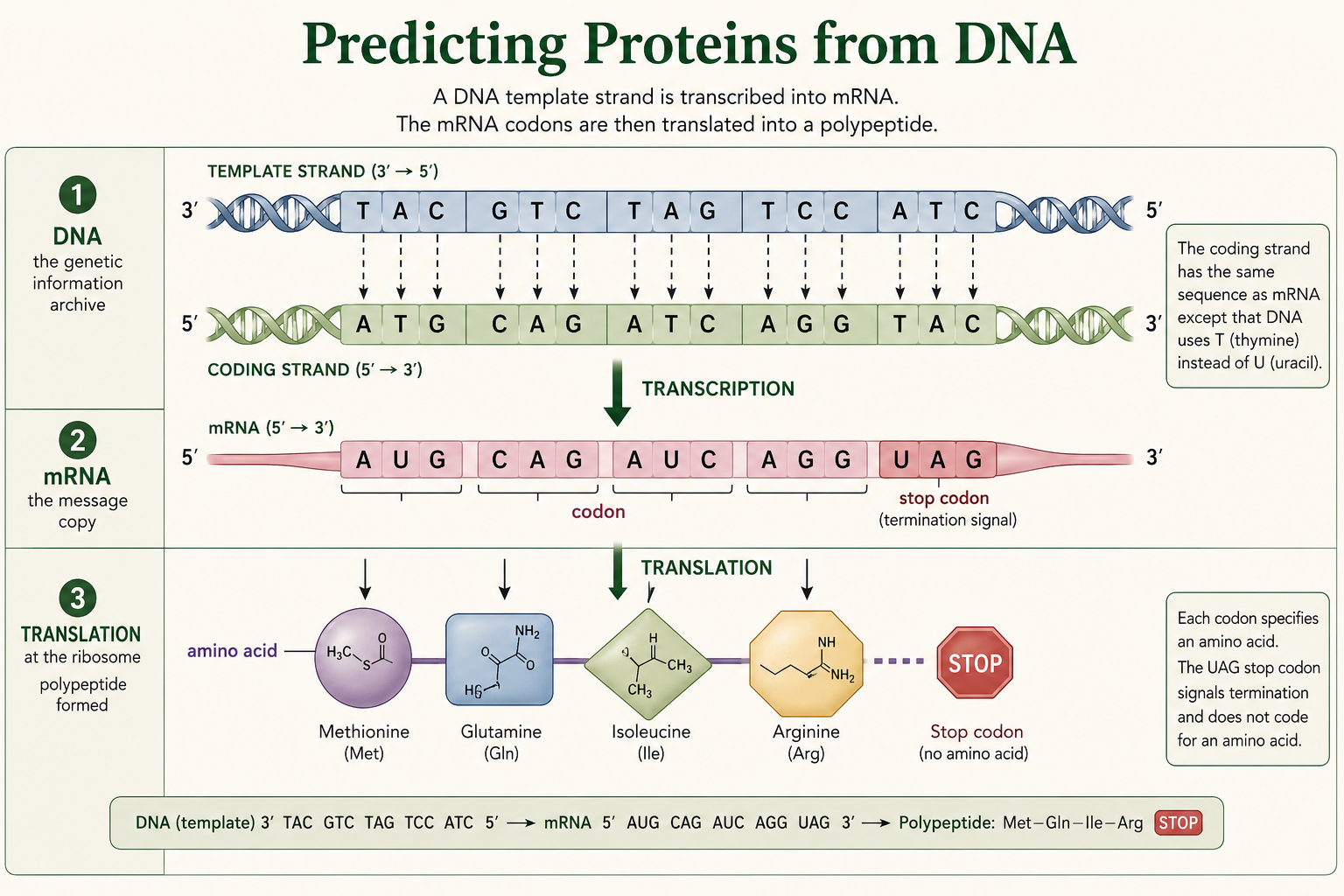
Predicting Amino Acids from a DNA Template Strand
Transcribe the DNA template strand into mRNA, divide the mRNA into codons, and use the genetic code to identify the first three amino acids in the predicted protein sequence.
Instructions
The strand below is a DNA template strand, written 3′ to 5′. First, transcribe the template strand into mRNA written 5′ to 3′. Then divide the mRNA into three-base codons. Finally, use the genetic code chart to identify the first three amino acids.
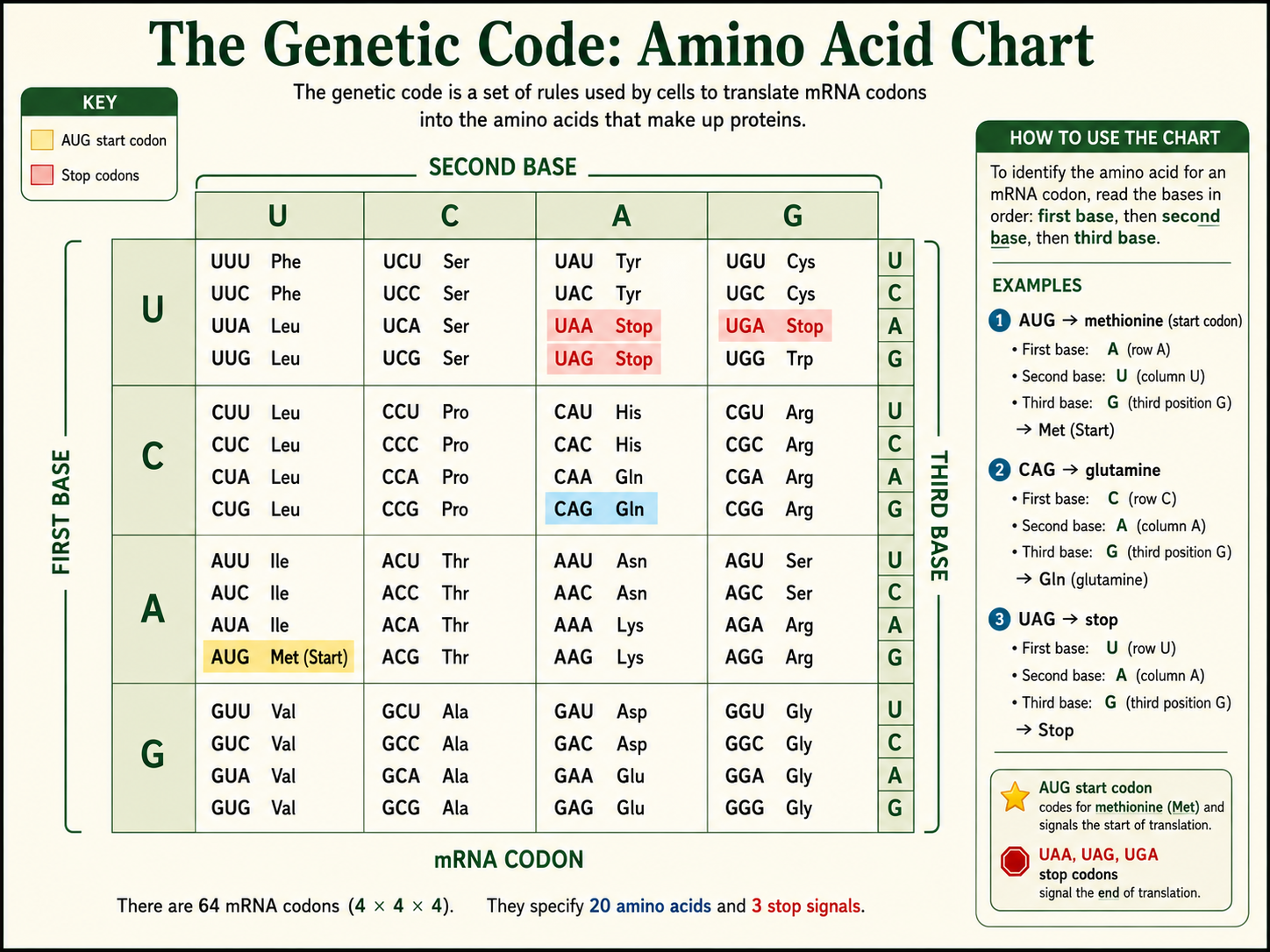
Amino Acid Chart
This chart uses mRNA codons. Read each codon by identifying its first base, second base, and third base. Do not use DNA triplets in the chart.
| First base | Second base U | Second base C | Second base A | Second base G |
|---|---|---|---|---|
| U |
UUUPhenylalanine
UUCPhenylalanine
UUALeucine
UUGLeucine
|
UCUSerine
UCCSerine
UCASerine
UCGSerine
|
UAUTyrosine
UACTyrosine
UAAStop
UAGStop
|
UGUCysteine
UGCCysteine
UGAStop
UGGTryptophan
|
| C |
CUULeucine
CUCLeucine
CUALeucine
CUGLeucine
|
CCUProline
CCCProline
CCAProline
CCGProline
|
CAUHistidine
CACHistidine
CAAGlutamine
CAGGlutamine
|
CGUArginine
CGCArginine
CGAArginine
CGGArginine
|
| A |
AUUIsoleucine
AUCIsoleucine
AUAIsoleucine
AUGMethionine / Start
|
ACUThreonine
ACCThreonine
ACAThreonine
ACGThreonine
|
AAUAsparagine
AACAsparagine
AAALysine
AAGLysine
|
AGUSerine
AGCSerine
AGAArginine
AGGArginine
|
| G |
GUUValine
GUCValine
GUAValine
GUGValine
|
GCUAlanine
GCCAlanine
GCAAlanine
GCGAlanine
|
GAUAspartic acid
GACAspartic acid
GAAGlutamic acid
GAGGlutamic acid
|
GGUGlycine
GGCGlycine
GGAGlycine
GGGGlycine
|
Quiz: Identify the First Three Amino Acids
Select the amino acid coded by each of the first three mRNA codons. Remember: the amino acid chart is read using mRNA codons, not DNA triplets.
How to Work Through the Sequence
The amino acid chart is read using mRNA codons. The DNA template strand must be transcribed into mRNA first.
- DNA template: 3′ - TAC GTC TAG TCC ATC - 5′
- mRNA: 5′ - AUG CAG AUC AGG UAG - 3′
- Codons: AUG | CAG | AUC | AGG | UAG
- First three amino acids: methionine, glutamine, isoleucine